Documents
Presentation Slides
Recursive Joint Attention for Audio-Visual Fusion in Regression-Based Emotion Recognition
- Citation Author(s):
- Submitted by:
- Gnana Praveen R...
- Last updated:
- 19 May 2023 - 2:32pm
- Document Type:
- Presentation Slides
- Document Year:
- 2023
- Event:
- Presenters:
- Gnana Praveen Rajasekhar
- Paper Code:
- 5309
- Categories:
- Log in to post comments
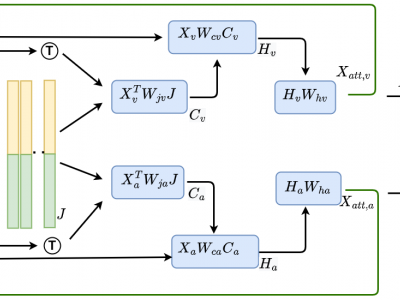
In video-based emotion recognition (ER), it is important to effectively leverage the complementary relationship among audio (A) and visual (V) modalities, while retaining the intramodal characteristics of individual modalities. In this paper, a recursive joint attention model is proposed along with long short-term memory (LSTM) modules for the fusion of vocal and facial expressions in regression-based ER. Specifically, we investigated the possibility of exploiting the complementary nature of A and V modalities using a joint cross-attention model in a recursive fashion with LSTMs to capture the intramodal temporal dependencies within the same modalities as well as among the A-V feature representations. By integrating LSTMs with recursive joint cross-attention, our model can efficiently leverage both intra- and inter-modal relationships for the fusion of A and V modalities. The results of extensive experiments performed on the challenging Affwild2 and Fatigue (private) datasets indicate that the proposed A-V fusion model can significantly outperform state-of-art-methods.

