
IEEE ICASSP 2023 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2023 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
- Read more about JAMMING SOURCE LOCALIZATION USING AUGMENTED PHYSICS-BASED MODEL
- Log in to post comments
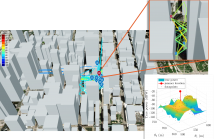
Monitoring interferences to satellite-based navigation systems is of paramount importance in order to reliably operate critical infrastructures, navigation systems, and a variety of applications relying on satellite-based positioning. This paper investigates the use of crowdsourced data to achieve such detection and monitoring at a central node that receives the data from an arbitrary number of agents in an area of interest. Under ideal conditions, the pathloss model is used to compute the Cramér-Rao Bound of accuracy as well as the corresponding maximum likelihood estimator.
- Categories:
 40 Views
40 Views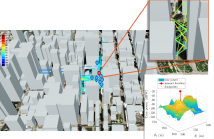
- Read more about JAMMING SOURCE LOCALIZATION USING AUGMENTED PHYSICS-BASED MODEL
- Log in to post comments
Monitoring interferences to satellite-based navigation systems is of paramount importance in order to reliably operate critical infrastructures, navigation systems, and a variety of applications relying on satellite-based positioning. This paper investigates the use of crowdsourced data to achieve such detection and monitoring at a central node that receives the data from an arbitrary number of agents in an area of interest. Under ideal conditions, the pathloss model is
- Categories:
34 Views
- Read more about BRAIN STRUCTURE-FUNCTION INTERACTION NETWORK FOR FLUID COGNITION PREDICTION
- Log in to post comments
Predicting fluid cognition via neuroimaging data is essential for understanding the neural mechanisms underlying various complex cognitions in the human brain. Both brain functional connectivity (FC) and structural connectivity (SC) provide distinct neural mechanisms for fluid cognition. In addition, interactions between SC and FC within distributed association regions are related to improvements in fluid cognition. However, existing learning-based methods that leverage both modality-specific embeddings and high-order interactions between the two modalities for prediction are scarce.
- Categories:
33 Views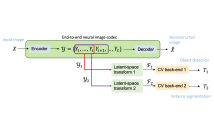
- Read more about Visual Coding for Humans and Machines
- Log in to post comments
Visual content is increasingly being used for more than human viewing. For example, traffic video is automatically analyzed to count vehicles, detect traffic violations, estimate traffic intensity, and recognize license plates; images uploaded to social media are automatically analyzed to detect and recognize people, organize images into thematic collections, and so on; visual sensors on autonomous vehicles analyze captured signals to help the vehicle navigate, avoid obstacles, collisions, and optimize their movement.
- Categories:
413 Views
- Read more about Building Blocks for a Complex-Valued Transformer Architecture
- Log in to post comments
Most deep learning pipelines are built on real-valued operations to deal with real-valued inputs such as images, speech or music signals. However, a lot of applications naturally make use of complex-valued signals or images, such as MRI or remote sensing. Additionally the Fourier transform of signals is complex-valued and has numerous applications. We aim to make deep learning directly applicable to these complex-valued signals without using projections into R2 .
- Categories:
65 Views
With the integration of communication and computing, it is expected that part of the computing is transferred to the transmitter side. In this paper we address the general problem of Frequency Modulation (FM) for function approximation through a communication channel. We exploit the benefits of the Discrete Cosine Transform (DCT) to approximate the function and design the waveform. In front of other approximation schemes, the DCT uses basis of controlled dynamic, which is a desirable property for a practical implementation.
- Categories:
43 Views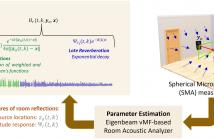
- Read more about Room Impulse Response Reconstruction Based on Spatio-Temporal-Spectral Features Learned from a Spherical Microphone Array Measurement
- Log in to post comments
Large-scale Room Impulse Response (RIR) measurements are required to accurately determine a room's acoustic response to different source-listener configurations. RIR reconstruction methods are often used to reduce these measurement costs. Prior knowledge of room acoustic parameters can ensure reliable and robust RIR reconstruction. This paper proposes a method to reconstruct RIRs based on reflection source locations and time-frequency-direction-dependent reflection magnitude response estimated from a single spherical microphone array measurement.
- Categories:
77 Views
- Read more about SLIDES - Real-Time Multichannel Speech Separation And Enhancement Using A Beamspace-Domain-Based Lightweight CNN
- Log in to post comments
The problems of speech separation and enhancement concern the extraction of the speech emitted by a target speaker when placed in a scenario where multiple interfering speakers or noise are present, respectively. A plethora of practical applications such as home assistants and teleconferencing require some sort of speech separation and enhancement pre-processing before applying Automatic Speech Recognition (ASR) systems. In the recent years, most techniques have focused on the application of deep learning to either time-frequency or time-domain representations of the input audio signals.
- Categories:
42 Views
- Read more about Annotated Pedestrians: A Dataset for Soft Biometrics Estimation for Varying Distances
- Log in to post comments
Following the significance of soft biometrics to facilitate seamless recognition or retrieval, the need for multi-modality annotated datasets is increasing - to evaluate any standalone soft biometrics system. Although, large-size datasets like PETA were annotated to evaluate soft biometrics systems, however, they were mainly annotated for global soft biometrics such as gender and age and for clothing modality.
- Categories:
94 Views
- Read more about Interpreting Intermediate Convolutional Layers of Generative CNNs Trained on Waveforms
- Log in to post comments
This paper presents a technique to interpret and visualize intermediate layers in generative CNNs trained on raw speech data in an unsupervised manner. We argue that averaging over feature maps after ReLU activation in each transpose convolutional layer yields interpretable time-series data. This technique allows for acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information.
- Categories:
53 Views