Documents
Poster
Retrieving speech samples with similar emotional content using a triplet loss function
- Citation Author(s):
- Submitted by:
- Carlos Busso
- Last updated:
- 20 May 2020 - 9:50am
- Document Type:
- Poster
- Document Year:
- 2019
- Event:
- Presenters:
- John Harvill
- Categories:
- Log in to post comments
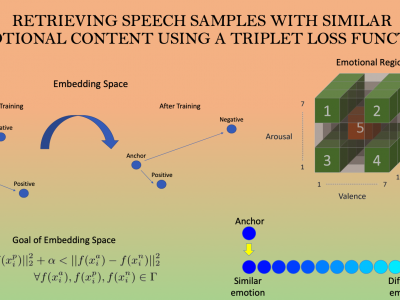
The ability to identify speech with similar emotional content is valuable to many applications, including speech retrieval, surveil- lance, and emotional speech synthesis. While current formulations in speech emotion recognition based on classification or regression are not appropriate for this task, solutions based on preference learn- ing offer appealing approaches for this task. This paper aims to find speech samples that are emotionally similar to an anchor speech sample provided as a query. This novel formulation opens interest- ing research questions. How well can a machine complete this task? How does the accuracy of automatic algorithms compare to the per- formance of a human performing this task? This study addresses these questions by training a deep learning model using a triplet loss function, mapping the acoustic features into an embedding that is discriminative for this task. The network receives an anchor speech sample and two competing speech samples, and the task is to deter- mine which of the candidate speech sample conveys the closest emo- tional content to the emotion conveyed by the anchor. By compar- ing the results from our model with human perceptual evaluations, this study demonstrates that the proposed approach has performance very close to human performance in retrieving samples with similar emotional content.

