Documents
Presentation Slides
SLAP: A Split Latency Adaptive VLIW Pipeline Architecture which enables on-the-fly Variable SIMD Vector Length
- Citation Author(s):
- Submitted by:
- Alan Gatherer
- Last updated:
- 19 June 2021 - 6:06pm
- Document Type:
- Presentation Slides
- Document Year:
- 2021
- Event:
- Presenters:
- Alan Gatherer
- Paper Code:
- ASPS-1.4
- Categories:
- Log in to post comments
Over the last decade the relative latency of access to shared memory by multicore increased as wire resistance dominated latency and low wire density layout pushed multi-port memories farther away from their ports. Various techniques were deployed to improve average memory access latencies, such as speculative pre-fetching and branch-prediction, often leading to high variance in execution time which is unacceptable in real-time systems. Smart DMAs can be used
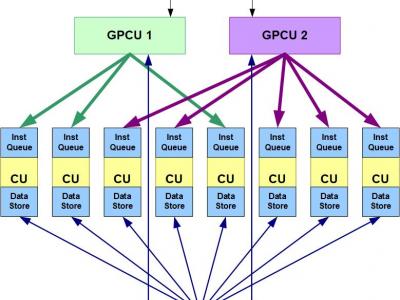
to directly copy data into a layer-1 SRAM, but with overhead. The VLIW architecture, the de-facto signal-processing engine, suffers badly from a breakdown in lock-step execution of scalar and vector instructions. We describe the Split Latency Adaptive Pipeline (SLAP) VLIW architecture, a cache performance improvement technology that requires zero change to object code, while removing smart DMAs and their overhead. SLAP builds on the Decoupled Access and
Execute concept by 1) breaking lock-step execution of functional units, 2) enabling variable vector length for variable data-level parallelism, and 3) adding a novel triangular-load mechanism. We discuss the SLAP architecture and demonstrate the performance benefits on real traces from a wireless baseband-system (where even the most compute intensive functions suffer from an Amdahl’s law limitation due to a mixture of scalar and vector processing).

