Documents
Presentation Slides
Towards Robust Visual Transformer Networks via K-Sparse Attention
- Citation Author(s):
- Submitted by:
- Sajjad Amini
- Last updated:
- 10 May 2022 - 5:11am
- Document Type:
- Presentation Slides
- Document Year:
- 2022
- Event:
- Presenters:
- Sajjad Amini
- Paper Code:
- MLSP-33.5
- Categories:
- Log in to post comments
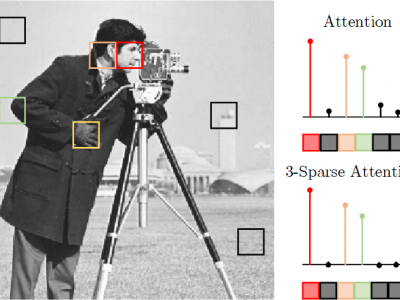
Transformer networks, originally developed in the community of machine translation to eliminate sequential nature of recurrent neural networks, have shown impressive results in other natural language processing and machine vision tasks. Self-attention is the core module behind visual transformers which globally mixes the image information. This module drastically reduces the intrinsic inductive bias imposed by CNNs, such as locality, while encountering insufficient robustness against some adversarial attacks. In this paper we introduce K-sparse attention to preserve low inductive bias, while robustifying transformers against adversarial attacks. We show that standard transformers attend values with dense set of weights, while the sparse attention, automatically selected by an optimization algorithm, can preserve generalization performance of the transformer and, at the same time, improve its robustness.

