Documents
Poster
Unsupervised Accent Adaptation Through Masked Language Model Correction Of Discrete Self-Supervised Speech Units
- DOI:
- 10.60864/qp3j-8683
- Citation Author(s):
- Submitted by:
- Jakob Poncelet
- Last updated:
- 6 June 2024 - 10:50am
- Document Type:
- Poster
- Document Year:
- 2024
- Event:
- Presenters:
- Jakob Poncelet
- Paper Code:
- SLP-P16.2
- Categories:
- Log in to post comments
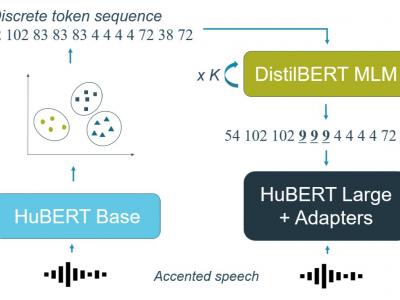
Self-supervised pre-trained speech models have strongly improved speech recognition, yet they are still sensitive to domain shifts and accented or atypical speech. Many of these models rely on quantisation or clustering to learn discrete acoustic units. We propose to correct the discovered discrete units for accented speech back to a standard pronunciation in an unsupervised manner. A masked language model is trained on discrete units from a standard accent and iteratively corrects an accented token sequence by masking unexpected cluster sequences and predicting their common variant. Small accent adapter blocks are inserted in the pre-trained model and fine-tuned by predicting the corrected clusters, which leads to an increased robustness of the pre-trained model towards a target accent, and this without supervision. We are able to improve a state-of-the-art HuBERT Large model on a downstream accented speech recognition task by altering the training regime with the proposed method.

