Documents
Poster
LEARNING COMPACT STRUCTURAL REPRESENTATIONS FOR AUDIO EVENTS USING REGRESSOR BANKS
- Citation Author(s):
- Submitted by:
- Huy Phan
- Last updated:
- 16 March 2016 - 9:03am
- Document Type:
- Poster
- Document Year:
- 2016
- Event:
- Presenters:
- Huy Phan
- Categories:
- Log in to post comments
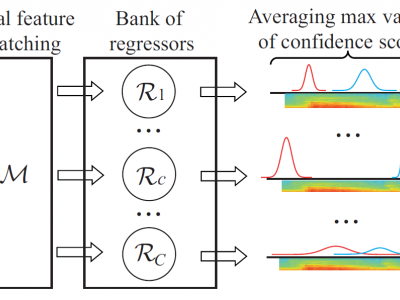
We introduce a new learned descriptor for audio signals which is efficient for event representation. The entries of the descriptor are produced by evaluating a set of regressors on the input signal. The regressors are class-specific and trained using the random regression forests framework. Given an input signal, each regressor estimates the onset and offset positions of the target event. The estimation confidence scores output by a regressor are then used to quantify how the target event aligns with the temporal structure of the corresponding category. Our proposed descriptor has two advantages. First, it is compact, i.e. the dimensionality of the descriptor is equal to the number of event classes. Second, we show that even simple linear classification models, trained on our descriptor, yield better accuracies on audio event classification task than not only the nonlinear baselines but also the state-of-the-art results.

