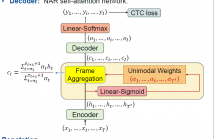
This paper works on non-autoregressive automatic speech recognition. A unimodal aggregation (UMA) is proposed to segment and integrate the feature frames that belong to the same text token, and thus to learn better feature representations for text tokens. The frame-wise features and weights are both derived from an encoder. Then, the feature frames with unimodal weights are integrated and further processed by a decoder. Connectionist temporal classification (CTC) loss is applied for training.
- Categories:
 31 Views
31 Views