- Read more about Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
- Log in to post comments
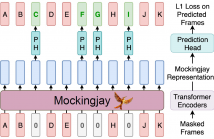
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts.
- Categories:
 53 Views
53 Views