| Type | Title | Author | Replies | Last updated |
|---|---|---|---|---|
| Document | NNSVS: A Neural Network-Based Singing Voice Synthesis Toolkit | Ryuichi Yamamoto | 0 | 2 years 4 months ago |
| Document | Parallel waveform synthesis based on generative adversarial networks with voicing-aware conditional discriminators | Ryuichi Yamamoto | 0 | 4 years 9 months ago |
| Document | PARALLEL WAVEGAN: A FAST WAVEFORM GENERATION MODEL BASED ON GENERATIVE ADVERSARIAL NETWORKS WITH MULTI-RESOLUTION SPECTROGRAM | Ryuichi Yamamoto | 0 | 5 years 10 months ago |
Primary tabs
Author's Documents

1 June 2023 - 6:21am 856 Downloads
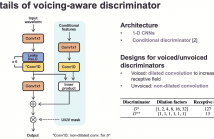
26 June 2021 - 2:38am 550 Downloads
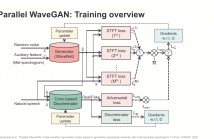
13 May 2020 - 10:56pm 766 Downloads