- Transducers
- Spatial and Multichannel Audio
- Source Separation and Signal Enhancement
- Room Acoustics and Acoustic System Modeling
- Network Audio
- Audio for Multimedia
- Audio Processing Systems
- Audio Coding
- Audio Analysis and Synthesis
- Active Noise Control
- Auditory Modeling and Hearing Aids
- Bioacoustics and Medical Acoustics
- Music Signal Processing
- Loudspeaker and Microphone Array Signal Processing
- Echo Cancellation
- Content-Based Audio Processing

- Read more about AN ATTENTION ENHANCED MULTI-TASK MODEL FOR OBJECTIVE SPEECH ASSESSMENT IN REAL-WORLD ENVIRONMENTS
- Log in to post comments
slide_1603.pdf
- Categories:
 15 Views
15 Views
- Read more about URTIS: A SMALL 3D IMAGING SONAR SENSOR FOR ROBOTIC APPLICATIONS
- Log in to post comments
- Categories:
20 Views
- Read more about AUDIO CODEC ENHANCEMENT WITH GENERATIVE ADVERSARIAL NETWORKS
- Log in to post comments
Audio codecs are typically transform-domain based and efficiently code stationary audio signals, but they struggle with speech and signals containing dense transient events such as applause. Specifically, with these two classes of signals as examples, we demonstrate a technique for restoring audio from coding noise based on generative adversarial networks (GAN). A primary advantage of the proposed GAN-based coded audio enhancer is that the method operates end-to-end directly on decoded audio samples, eliminating the need to design any manually-crafted frontend.
- Categories:
67 Views
- Categories:
5 Views
- Read more about Learning with Out of Distribution Data for Audio Classification
- Log in to post comments
In supervised machine learning, the assumption that training data is labelled correctly is not always satisfied. In this paper, we investigate an instance of labelling error for classification tasks in which the dataset is corrupted with out-of-distribution (OOD) instances: data that does not belong to any of the target classes, but is labelled as such. We show that detecting and relabelling certain OOD instances, rather than discarding them, can have a positive effect on learning.
- Categories:
15 Views
This paper presents a domain adaptation model for sound event detection. A common challenge for sound event detection is how to deal with the mismatch among different datasets. Typically, the performance of a model will decrease if it is tested on a dataset which is different from the one that the model is trained on. To address this problem, based on convolutional recurrent neural networks (CRNNs), we propose an adapted CRNN (A-CRNN) as an unsupervised adversarial domain adaptation model for sound event detection.
- Categories:
103 Views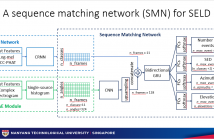
- Read more about A Sequence Matching Network for Polyphonic Sound Event Localization and Detection
- Log in to post comments
Polyphonic sound event detection and direction-of-arrival estimation require different input features from audio signals. While sound event detection mainly relies on time-frequency patterns, direction-of-arrival estimation relies on magnitude or phase differences between microphones. Previous approaches use the same input features for sound event detection and direction-of-arrival estimation, and train the two tasks jointly or in a two-stage transfer-learning manner.
- Categories:
66 Views- Read more about HIGH PERFORMANCE SUPERVISED TIME-DELAY ESTIMATION USING NEURAL NETWORKS
- Log in to post comments
Time-delay estimation is an essential building block of many signal processing applications. This paper follows up on earlier work for acoustic source localization and time delay estimation using pattern recognition techniques; it presents high performance results obtained with supervised training of neural networks which challenge the state of the art and compares its performance to that of well-known methods such as the Generalized Cross-Correlation or Adaptive Eigenvalue Decomposition.
- Categories:
82 Views
- Read more about WASPAA 2019 POSTER: MULTIPLE HYPOTHESIS TRACKING FOR OVERLAPPING SPEAKER SEGMENTATION
- Log in to post comments
Speaker segmentation is an essential part of any diarization system.Applications of diarization include tasks such as speaker indexing, improving automatic speech recognition (ASR) performance and making single speaker-based algorithms available for use in multi-speaker environments.This paper proposes a multiple hypothesis tracking (MHT) method that exploits the harmonic structure associated with the pitch in voiced speech in order to segment the onsets and end-points of speech from multiple, overlapping speakers.
- Categories:
73 Views