Documents
Presentation Slides
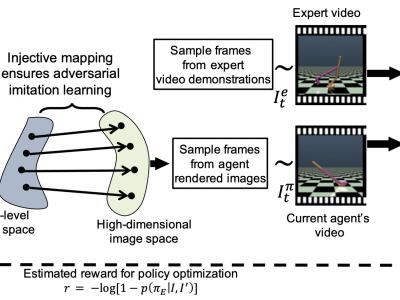
Injective State-Image Mapping facilitates Visual Adversarial Imitation Learning
- Citation Author(s):
- Submitted by:
- Subhajit Chaudhury
- Last updated:
- 24 September 2019 - 4:46pm
- Document Type:
- Presentation Slides
- Document Year:
- 2019
- Event:
- Presenters:
- Subhajit Chaudhury
- Paper Code:
- 32
- Categories:
- Log in to post comments
The growing use of virtual autonomous agents in applications like games and entertainment demands better control policies for natural-looking movements and actions. Unlike the conventional approach of hard-coding motion routines, we propose a deep learning method for obtaining control policies by directly mimicking raw video demonstrations. Previous methods in this domain rely on extracting low-dimensional features from expert videos followed by a separate hand-crafted reward estimation step. We propose an imitation learning framework that reduces the dependence on hand-engineered reward functions by jointly learning the feature extraction and reward estimation steps using Generative Adversarial Networks~(GANs). Our main contribution in this paper is to show that under injective mapping between low-level joint state (angles and velocities) trajectories and corresponding raw video stream, performing adversarial imitation learning on video demonstrations is equivalent to learning from the state trajectories. Experimental results show that the proposed adversarial learning method from raw videos produces a similar performance to state-of-the-art imitation learning techniques while frequently outperforming existing hand-crafted video imitation methods. Furthermore, we show that our method can learn action policies by imitating video demonstrations on YouTube with similar performance to learned agents from true reward signal. Please see the supplementary video submission at https://ibm.biz/BdzzNA.

