Documents
Presentation Slides
Presentation Slides
Motion Dynamics Improve Speaker-Independent Lipreading
- Citation Author(s):
- Submitted by:
- Matteo Riva
- Last updated:
- 19 April 2020 - 6:19pm
- Document Type:
- Presentation Slides
- Document Year:
- 2020
- Event:
- Presenters:
- Matteo Riva
- Paper Code:
- 4996
- Categories:
- Log in to post comments
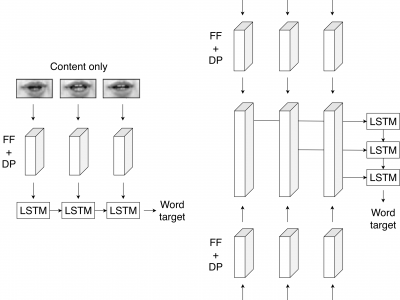
We present a novel lipreading system that improves on the task of speaker-independent word recognition by decoupling motion and content dynamics. We achieve this by implementing a deep learning architecture that uses two distinct pipelines to process motion and content and subsequently merges them, implementing an end-to-end trainable system that performs fusion of independently learned representations. We obtain a average relative word accuracy improvement of ≈6.8% on unseen speakers and of ≈3.3% on known speakers, with respect to a baseline which uses a standard architecture.

