- Read more about On-Device Constrained Self-Supervised Learning for Keyword Spotting via Quantization Aware Pre-Training and Fine-tuning
- Log in to post comments
Large self-supervised models have excelled in various speech processing tasks, but their deployment on resource-limited devices is often impractical due to their substantial memory footprint. Previous studies have demonstrated the effectiveness of self-supervised pre-training for keyword spotting, even with constrained model capacity.
final_v5.pdf
- Categories:
 35 Views
35 Views- Read more about Are Soft prompts good zero-shot learners for speech recognition?
- Log in to post comments
Large self-supervised pre-trained speech models require computationally expensive fine-tuning for downstream tasks. Soft prompt tuning offers a simple parameter-efficient alternative by utilizing minimal soft prompt guidance, enhancing portability while also maintaining competitive performance. However, not many people understand how and why this is so. In this study, we aim to deepen our understanding of this emerging method by investigating the role of soft prompts in automatic speech recognition (ASR).
- Categories:
32 Views
- Read more about Towards Better Meta-Initialization with Task Augmentation for Kindergarten-aged Speech Recognition
- Log in to post comments
Children's automatic speech recognition (ASR) is always difficult due to, in part, the data scarcity problem, especially for kindergarten-aged kids. When data are scarce, the model might overfit to the training data, and hence good starting points for training are essential. Recently, meta-learning was proposed to learn model initialization (MI) for ASR tasks of different languages. This method leads to good performance when the model is adapted to an unseen language. However, MI is vulnerable to overfitting on training tasks (learner overfitting).
- Categories:
13 Views
We propose a new meta learning based framework for low resource speech recognition that improves the previous model agnostic meta learning (MAML) approach. The MAML is a simple yet powerful meta learning approach. However, the MAML presents some core deficiencies such as training instabilities and slower convergence speed. To address these issues, we adopt multi-step loss (MSL). The MSL aims to calculate losses at every step of the inner loop of MAML and then combines them with a weighted importance vector.
- Categories:
37 Views
- Read more about Punctuation Prediction for Streaming On-Device Speech Recognition
- Log in to post comments
Punctuation prediction is essential for automatic speech recognition (ASR). Although many works have been proposed for punctuation prediction, the on-device scenarios are rarely discussed with an end-to-end ASR. The punctuation prediction task is often treated as a post-processing of ASR outputs, but the mismatch between natural language in training input and ASR hypotheses in testing is ignored. Besides, language models built with deep neural networks are too large for edge devices.
- Categories:
22 Views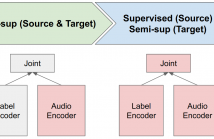
- Read more about Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
- Log in to post comments
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model.
- Categories:
35 Views
- Read more about BI-APC: BIDIRECTIONAL AUTOREGRESSIVE PREDICTIVE CODING FOR UNSUPERVISED PRE-TRAINING AND ITS APPLICATION TO CHILDREN’S ASR
- Log in to post comments
We present a bidirectional unsupervised model pre-training (UPT) method and apply it to children’s automatic speech recognition (ASR). An obstacle to improving child ASR is the scarcity of child speech databases. A common approach to alleviate this problem is model pre-training using data from adult speech. Pre-training can be done using supervised (SPT) or unsupervised methods, depending on the availability of annotations. Typically, SPT performs better. In this paper, we focus on UPT to address the situations when pre-training data are unlabeled.
- Categories:
22 Views
- Read more about Libri-Light: A Benchmark for ASR with Limited or No Supervision- ICASSP 2020 Slides
- Log in to post comments
- Categories:
165 Views
- Read more about SPEECH RECOGNITION MODEL COMPRESSION
- Log in to post comments
Deep Neural Network-based speech recognition systems are widely used in most speech processing applications. To achieve better model robustness and accuracy, these networks are constructed with millions of parameters, making them storage and compute-intensive. In this paper, we propose Bin & Quant (B&Q), a compression technique using which we were able to reduce the Deep Speech 2 speech recognition model size by 7 times for a negligible loss in accuracy.
- Categories:
54 Views
- Read more about CROSS LINGUAL TRANSFER LEARNING FOR ZERO-RESOURCE DOMAIN ADAPTATION
- Log in to post comments
We propose a method for zero-resource domain adaptation of DNN acoustic models, for use in low-resource situations where the only in-language training data available may be poorly matched to the intended target domain. Our method uses a multi-lingual model in which several DNN layers are shared between languages. This architecture enables domain adaptation transforms learned for one well-resourced language to be applied to an entirely different low- resource language.
- Categories:
25 Views