
Welcome to IASL 2016 - November 21-23, 2016, Tainan, Taiwan
The International Conference on Asian Language Processing (IALP) is a series of conferences with unique focus on Asian Language Processing. The conference aims to advance the science and technology of all the aspects of Asian Language Processing by providing a forum for researchers in the different fields of language study all over the world to meet.

- Read more about Towards Building a Standard Dataset for Arabic Keyphrase Extraction Evaluation
- Log in to post comments
Keyphrases are short phrases that best represent a document content. They can be useful in a variety of applications, including document summarization and retrieval models. In this paper, we introduce the first dataset of keyphrases for an Arabic document collection, obtained by means of crowdsourcing. We experimentally evaluate different crowdsourced answer aggregation strategies and validate their performances against expert annotations to evaluate the quality of our dataset. We report about our experimental results, the dataset features, some lessons learned, and ideas for future
- Categories:
 6 Views
6 Views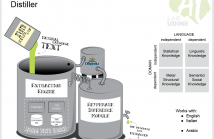
- Read more about Leveraging Arabic Morphology and Syntax for Achieving Better Keyphrase Extraction
- Log in to post comments
Arabic is one of the fastest growing languages on the Web, with an increasing amount of user generated content being published by both native and non-native speakers all over the world. Despite the great linguistic differences between Arabic and western languages such as English, most Arabic keyphrase extraction systems rely on approaches designed for western languages, thus ignoring its rich morphology and syntax. In this paper we present a new approach leveraging the Arabic morphology and syntax to generate a restricted set of meaningful candidates among which keyphrases are selected.
- Categories:
44 Views- Read more about Annotating Chinese Noun Phrases Based on Semantic Dependency Graph
- Log in to post comments
Annotating complicated noun phrases is a difficulty in semantic analysis. In this paper we investigate the annotation methods of noun phrases in Nombank, Chinese Nombank and Sinica Treebank trying to propose an annotation scheme based on semantic dependency graph for noun phrases.
- Categories:
6 Views- Read more about Dimensional Sentiment Analysis of Traditional Chinese Words Using Pre-trained Not-quite-right Sentiment Word Vectors and Supervised Ensemble Models
- Log in to post comments
This work focuses on two specific types of sentimental information analysis for traditional Chinese words, i.e., valence represents the degree of pleasant and unpleasant feelings (i.e., sentiment orientation), and arousal represents the degree of excitement and calm (i.e., sentiment strength). To address it, we proposed supervised ensemble learning models to assign appropriate real valued ratings to each
- Categories:
17 Views- Read more about Importance Weighted Feature Selection Strategy for Text Classification
- Log in to post comments
Feature selection, which aims at obtaining a compact and effective feature subset for better performance and higher efficiency, has been studied for decades. The traditional feature selection metrics, such as Chi-square and information gain, fail to consider how important a feature is in a document. Features, no matter how much effective semantic information they hold, are treated equally. Intuitively, thus calculated feature selection metrics are very likely to introduce much noise. We, therefore, in this study, extend the work of Li et al.
- Categories:
7 Views- Read more about Learning Dimensional Sentiment of Traditional Chinese Words with Word Embedding and Support Vector Regression
- Log in to post comments
Dimensional sentiment analysis approach, which represents affective states as continuous numerical values on multiple dimensions, such as valence-arousal (VA) space, allows for more fine-grained analysis than the traditional categorical approach. In recent years, it has been applied in applications such as antisocial behavior detection, mood analysis and product review ranking. In this approach, an affective lexicon with dimensional sentiment values is a key resource, but building such a lexicon costs much.
- Categories:
11 Views- Read more about Improved Arabic Characters Recognition by Combining Multiple Machine Learning Classifiers
- Log in to post comments
In this paper, we investigate a range of
strategies for combining multiple machine learning
techniques for recognizing Arabic characters, where we
are faced with imperfect and dimensionally variable input
characters. Experimental results show that combined
confidence-based backoff strategies can produce more
accurate results than each technique produces by itself
and even the ones exhibited by the majority voting
combination.
Poster.pdf
- Categories:
8 Views- Read more about A Semi-automatic Approach to Identifying and Unifying Ambiguously Encoded Arabic-Based Characters
- Log in to post comments
In this study, we outline a potential problem
in normalising texts that are based on a modified version
of the Arabic alphabet. One of the main resources
available for processing resource-scarce languages is
raw text collected from the Internet. Many less-
resourced languages, such as Kurdish, Farsi, Urdu,
Pashtu, etc., use a modified version of the Arabic writing
system. Many characters in harvested data from the
Internet may have exactly the same form but encoded
with different Unicode values (ambiguous characters).
- Categories:
8 Views- Read more about Semantic Annotation for Mandarin Verbal Lexicon
- Log in to post comments
This study examines the challenging issues in the semantic annotation of the characteristics of verbal information of Mandarin Chinese. It proposes a frame-based constructional approach that aligns with linguistic premises in Frame Semantics, Construction Grammar and Cognitive Grammar. Given that semantic processing has a lot to do with human cognitive capacities, semantic transfer and profile on the basis of natural inferences of event chains have to be considered in verb categorization and representation.
- Categories:
24 Views- Read more about Dialog State Tracking and Action Selection Using Deep Learning Mechanism for Interview Coaching
- Log in to post comments
The best way to prepare for an interview is to review the different types of possible interview questions you will be asked during an interview and practice responding to questions. An interview coaching system tries to simulate an interviewer to provide mock interview practice simulation sessions for the users. The traditional interview coaching systems provide some feedbacks, including facial preference, head nodding, response time, speaking rate, and volume, to let users know their own performance in the mock interview.
- Categories:
25 Views