Documents
Poster
LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders
- Citation Author(s):
- Submitted by:
- Rodrigo Mira
- Last updated:
- 29 May 2023 - 8:32am
- Document Type:
- Poster
- Document Year:
- 2023
- Event:
- Presenters:
- Rodrigo Mira
- Paper Code:
- 2499
- Categories:
- Keywords:
- Log in to post comments
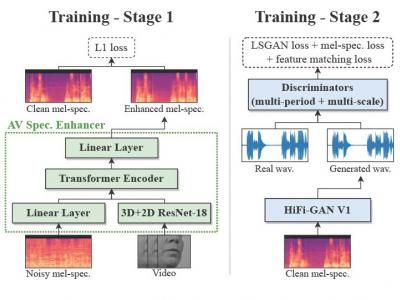
Audio-visual speech enhancement aims to extract clean speech from a noisy environment by leveraging not only the audio itself but also the target speaker's lip movements. This approach has been shown to yield improvements over audio-only speech enhancement, particularly for the removal of interfering speech. Despite recent advances in speech synthesis, most audio-visual approaches continue to use spectral mapping/masking to reproduce the clean audio, often resulting in visual backbones added to existing speech enhancement architectures. In this work, we propose LA-VocE, a new two-stage approach that predicts mel-spectrograms from noisy audio-visual speech via a transformer-based architecture, and then converts them into waveform audio using a neural vocoder (HiFi-GAN). We train and evaluate our framework on thousands of speakers and 11+ different languages, and study our model's ability to adapt to different levels of background noise and speech interference. Our experiments show that LA-VocE outperforms existing methods according to multiple metrics, particularly under very noisy scenarios.

