Documents
Poster
MULTI-EXIT VISION TRANSFORMER WITH CUSTOM FINE-TUNING FOR FINE-GRAINED IMAGE RECOGNITION
- DOI:
- 10.60864/g9xj-9146
- Citation Author(s):
- Submitted by:
- Tianyi Shen
- Last updated:
- 17 November 2023 - 12:05pm
- Document Type:
- Poster
- Document Year:
- 2023
- Event:
- Presenters:
- Tianyi Shen
- Paper Code:
- 2852
- Categories:
- Keywords:
- Log in to post comments
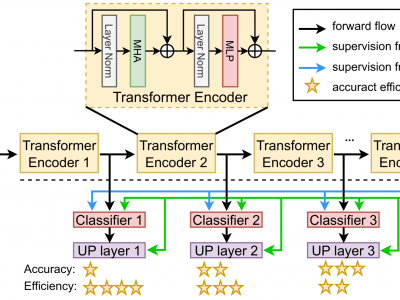
Capturing subtle visual differences between subordinate categories is crucial for improving the performance of Finegrained Visual Classification (FGVC). Recent works proposed deep learning models based on Vision Transformer (ViT) to take advantage of its self-attention mechanism to locate important regions of the objects and extract global information. However, their large number of layers with self-attention mechanism requires intensive computational cost and makes them impractical to be deployed on resource-restricted hardware including internet of things (IoT) devices. In this work, we propose a novel Multi-exit Vision Transformer architecture (MEViT) for early exiting based on ViT, as well as a fine-tuning strategy that involves self-distillation to improve the accuracy of early exit branches on FGVC task compared to the baseline ViT model. The experiments on two standard FGVC benchmarks show our proposed model provides superior accuracy-efficiency trade-offs compared to the state-of-the-art (SOTA) ViT-based model and demonstrate that it is possible to accurately classify many subcategories with significantly less effort.

