- Read more about ARTIFICIALLY SYNTHESISING DATA FOR AUDIO CLASSIFICATION AND SEGMENTATION TO IMPROVE SPEECH AND MUSIC DETECTION IN RADIO BROADCAST
- Log in to post comments
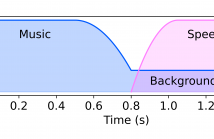
Segmenting audio into homogeneous sections such as music and speech helps us understand the content of audio. It is useful as a pre-processing step to index, store, and modify audio recordings, radio broadcasts and TV programmes. Deep learning models for segmentation are generally trained on copyrighted material, which cannot be shared. Annotating these datasets is time-consuming and expensive and therefore, it significantly slows down research progress. In this study, we present a novel procedure that artificially synthesises data that resembles radio signals.
- Categories:
 22 Views
22 Views
- Read more about ZERO-SHOT AUDIO CLASSIFICATION WITH FACTORED LINEAR AND NONLINEAR ACOUSTIC-SEMANTIC PROJECTIONS
- Log in to post comments
In this paper, we study zero-shot learning in audio classification through factored linear and nonlinear acoustic-semantic projections between audio instances and sound classes. Zero-shot learning in audio classification refers to classification problems that aim at recognizing audio instances of sound classes, which have no available training data but only semantic side information. In this paper, we address zero-shot learning by employing factored linear and nonlinear acoustic-semantic projections.
- Categories:
19 Views
