
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The 2019 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about Cofnet: Predict with Confidence
- Log in to post comments
POSTER.pdf
- Categories:
 7 Views
7 Views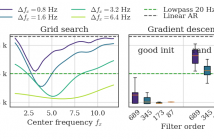
In non-linear autoregressive models, the time dependency of coefficients is often driven by a particular time-series which is not given and thus has to be estimated from the data. To allow model evaluation on a validation set, we describe a parametric approach for such driver estimation. After estimating the driver as a weighted sum of potential drivers, we use it in a non-linear autoregressive model with a polynomial parametrization. Using gradient descent, we optimize the linear filter extracting the driver, outperforming a typical grid-search on predefined filters.
- Categories:
1 Views
- Read more about INDIVIDUAL DIFFERENCE OF ULTRASONIC TRANSDUCERS FOR PARAMETRIC ARRAY LOUDSPEAKER
- Log in to post comments
A parametric array loudspeaker (PAL) consists of a lot of ultrasonic transducers in most cases and is driven by an ultrasonic which is modulated by audible sound. Because each ultrasonic transducer has each difference resonant frequency, there is the individual difference in ultrasonic transducers of a PAL in a manufacturing process. In this paper, two PALs are made of each set of transducers with large and small variance of resonant frequencies.
- Categories:
14 Views
- Read more about DEEP CNN BASED FEATURE EXTRACTOR FOR TEXT-PROMPTED SPEAKER RECOGNITION
- Log in to post comments
Deep learning is still not a very common tool in speaker verification field. We study deep convolutional neural network performance in the text-prompted speaker verification task. The prompted passphrase is segmented into word states — i.e. digits — to test each digit utterance separately. We train a single high-level feature extractor for all states and use cosine similarity metric for scoring. The key feature of our network is the Max-Feature-Map activation function, which acts as an embedded feature selector.
- Categories:
15 Views
- Read more about MULTI-SCENARIO DEEP LEARNING FOR MULTI-SPEAKER SOURCE SEPARATION
- Log in to post comments
Research in deep learning for multi-speaker source separation has received a boost in the last years. However, most studies are restricted to mixtures of a specific number of speakers, called a specific scenario. While some works included experiments for different scenarios, research towards combining data of different scenarios or creating a single model for multiple scenarios have been very rare. In this work it is shown that data of a specific scenario is relevant for solving another scenario.
- Categories:
10 Views
- Read more about CLUSTER-BASED POINT CLOUD CODING WITH NORMAL WEIGHTED GRAPH FOURIER TRANSFORM
- Log in to post comments
Point cloud has attracted more and more attention in 3D object representation, especially in free-view rendering. However, it is challenging to efficiently deploy the point cloud due to its huge data amount with multiple attributes including coordinates, normal and color. In order to represent point clouds more compactly, we propose a novel point cloud compression method for attributes, based on geometric clustering and Normal Weighted Graph Fourier Transform (NWGFT).
- Categories:
133 Views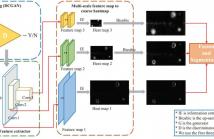
- Read more about A Generative Adversarial Network Based Framework For Unsupervised Visual Surface Inspection
- Log in to post comments
Visual surface inspection is a challenging task due to the highly inconsistent appearance of the target surfaces and the abnormal regions. Most of the state-of-the-art methods are highly dependent on the labelled training samples, which are difficult to collect in practical industrial applications. To address this problem, we propose a generative adversarial network based framework for unsupervised surface inspection. The generative adversarial network is trained to generate the fake images analogous to the normal surface images.
- Categories:
156 Views
- Read more about Generalised Sidelobe Canceller for noise reduction in hearing devices using an external microphone
- Log in to post comments
The use of an external microphone in conjunction with an existing local microphone array can be particularly beneficial for noise reduction tasks that are critical for hearing devices, such as cochlear implants and hearing aids. Recent work has already demonstrated how an external microphone signal can be effectively incorporated into the common noise reduction technique of using a Minimum Variance Distortionless Response (MVDR) beamformer.
- Categories:
17 Views
- Read more about PRIMA: PROBABILISTIC RANKING WITH INTER-ITEM COMPETITION AND MULTI-ATTRIBUTE UTILITY FUNCTION
- Log in to post comments
PRIMA4.pdf
- Categories:
13 Views