Documents
Poster
Articulation GAN: Unsupervised Modeling of Articulatory Learning
- DOI:
- 10.60864/q8dc-3114
- Citation Author(s):
- Submitted by:
- Gasper Begus
- Last updated:
- 17 November 2023 - 12:07pm
- Document Type:
- Poster
- Document Year:
- 2023
- Event:
- Presenters:
- Gasper Begus, Alan Zhou
- Paper Code:
- 5406
- Categories:
- Log in to post comments
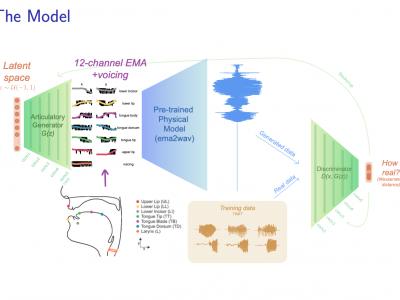
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm, a new unsupervised generative model of speech production/synthesis. The Articulatory Generator more closely mimics human speech production by learning to generate articulatory representations (electromagnetic articulography or EMA) in a fully unsupervised manner. A separate pre-trained physical model (ema2wav) then transforms the generated EMA representations to speech waveforms, which get sent to the Discriminator for evaluation. Articulatory analysis suggests that the network learns to control articulators in a similar manner to humans during speech production. Acoustic analysis of the outputs suggests that the network learns to generate words that are both present and absent in the training distribution. We additionally discuss implications of articulatory representations for cognitive models of human language and speech technology in general.

