- Read more about Interpreting Intermediate Convolutional Layers of Generative CNNs Trained on Waveforms
- Log in to post comments
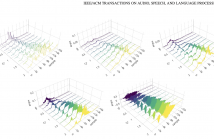
This paper presents a technique to interpret and visualize intermediate layers in generative CNNs trained on raw speech data in an unsupervised manner. We argue that averaging over feature maps after ReLU activation in each transpose convolutional layer yields interpretable time-series data. This technique allows for acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information.
- Categories:
 54 Views
54 Views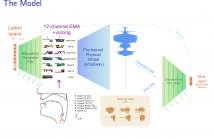
- Read more about Articulation GAN: Unsupervised Modeling of Articulatory Learning
- Log in to post comments
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm, a new unsupervised generative model of speech production/synthesis.
- Categories:
86 Views
This paper describes new reference benchmark results based on hybrid Hidden Markov Model and Deep Neural Networks (HMM-DNN) for the GlobalPhone (GP) multilingual text and speech database. GP is a multilingual database of high-quality read speech with corresponding transcriptions and pronunciation dictionaries in more than 20 languages. Moreover, we provide new results for five additional languages, namely, Amharic, Oromo, Tigrigna, Wolaytta, and Uyghur.
- Categories:
49 Views
- Read more about DEEP NEURAL NETWORKS BASED AUTOMATIC SPEECH RECOGNITION FOR FOUR ETHIOPIAN LANGUAGES
- Log in to post comments
In this work, we present speech recognition systems for four Ethiopian languages: Amharic, Tigrigna, Oromo and Wolaytta. We have used comparable training corpora of about 20 to 29 hours speech and evaluation speech of about 1 hour for each of the languages. For Amharic and Tigrigna, lexical and language models of different vocabulary size have been developed. For Oromo and Wolaytta, the training lexicons have been used for decoding.
- Categories:
157 Views
- Read more about SPOKEN LANGUAGE ACQUISITION BASED ON REINFORCEMENT LEARNING AND WORD UNIT SEGMENTATION
- Log in to post comments
The process of spoken language acquisition has been one of the topics which attract the greatest interesting from linguists for decades. By utilizing modern machine learning techniques, we simulated this process on computers, which helps to understand the mystery behind the process, and enable new possibilities of applying this concept on, but not limited to, intelligent robots. This paper proposes a new framework for simulating spoken language acquisition by combining reinforcement learning and unsupervised learning methods.
- Categories:
134 Views
- Read more about Combining Acoustics, Content and Interaction Features to Find Hot Spots in Meetings
- Log in to post comments
Involvement hot spots have been proposed as a useful concept for meeting analysis and studied off and on for over 15 years. These are regions of meetings that are marked by high participant involvement, as judged by human annotators. However, prior work was either not conducted in a formal machine learning setting, or focused on only a subset of possible meeting features or downstream applications (such as summarization). In this paper we investigate to what extent various acoustic, linguistic and pragmatic aspects of the meetings, both in isolation and jointly, can help detect hot spots.
- Categories:
19 Views
Data augmentation is crucial to improving the performance of deep neural networks by helping the model avoid overfitting and improve its generalization. In automatic speech recognition, previous work proposed several approaches to augment data by performing speed perturbation or spectral transformation. Since data augmented in these manners has similar acoustic representations with the original data, it has limited advantage in improving generalization of the acoustic model.
- Categories:
71 Views
- Read more about Models of visually grounded speech signal pay attention to nouns: a bilingual experiment on English and Japanese
- Log in to post comments
We investigate the behaviour of attention in neural models of visually grounded speech trained on two languages: English and Japanese. Experimental results show that attention focuses on nouns and this behaviour holds true for two very typologically different languages. We also draw parallels between artificial neural attention and human attention and show that neural attention focuses on word endings as it has been theorised for human attention. Finally, we investigate how two visually grounded monolingual models can be used to perform cross-lingual speech-to-speech retrieval.
- Categories:
16 Views- Read more about Tongue Performance in Articulating Mandarin Apical Syllables by Prelingual Deaf Adults Using Ultrasonic Technology: Two Case Studies
- Log in to post comments
In the present study, the ultrasonic data of two prelingual deaf participants were collected to observe tongue movements during the production of all the apical syllables under four citation tones except for \emph{ri} in Mandarin Chinese. Results of data analysis showed that, besides their personal characteristics, the two participants share similar problems in producing those apical syllables such as producing alveolar syllables as post-alveolar syllables, realizing affricates as fricatives, and unable to pronounce some types of apical syllables which they can perceive correctly.
- Categories:
9 Views- Read more about Investigation of the Effects of Automatic Scoring Technology on Human Raters' Performances in L2 Speech Proficiency Assessment
- Log in to post comments
This study investigates how automatic scorings based on speech technology can affect human raters' judgement of students' oral language proficiency in L2 speaking tests. Automatic scorings based on ASR are widely used in non-critical speaking tests or practices and relatively high correlations between machine scores and human scores have been reported. In high-stakes speaking tests, however, many teachers remain skeptical about the fairness of automatic scores given by machines even with the most advanced scoring methods.
- Categories:
14 Views