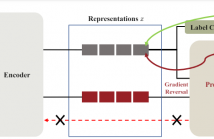
- Read more about Stethoscope-Guided Supervised Contrastive Learning for Cross-domain Adaptation on Respiratory Sound Classification
- Log in to post comments
Despite the remarkable advances in deep learning technology, achieving satisfactory performance in lung sound classification remains a challenge due to the scarcity of available data. Moreover, the respiratory sound samples are collected from a variety of electronic stethoscopes, which could potentially introduce biases into the trained models. When a significant distribution shift occurs within the test dataset or in a practical scenario, it can substantially decrease the performance.
- Categories:
 43 Views
43 Views- Read more about VOCAL FOLD DYNAMICS FOR AUTOMATIC DETECTION OF AMYOTROPHIC LATERAL SCLEROSIS FROM VOICE
- Log in to post comments
Amyotrophic Lateral Sclerosis (ALS) is a neurodegenerative disease that affects motor neurons and causes speech and respiratory dysfunctions. Current diagnostic methods are com- plicated, thus motivating the development of an efficient and objective diagnostic aid. We hypothesize that analyses of features capturing the essential characteristics of the biomechanical process of voice production can distinguish ALS patients from non-ALS controls. In this paper, we represent voices with algorithmically estimated vocal fold dynamics from physical models of phonation.
- Categories:
27 Views- Read more about Exploring Meta Information for Audio-based Zero-Shot Bird Classification
- Log in to post comments
Advances in passive acoustic monitoring and machine learning have led to the procurement of vast datasets for computational bioacoustic research. Nevertheless, data scarcity is still an issue for rare and underrepresented species. This
- Categories:
32 Views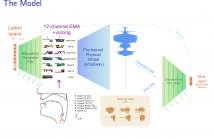
- Read more about Articulation GAN: Unsupervised Modeling of Articulatory Learning
- Log in to post comments
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm, a new unsupervised generative model of speech production/synthesis.
- Categories:
85 Views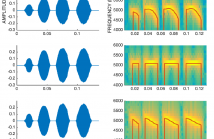
- Read more about ANALYSIS AND RE-SYNTHESIS OF NATURAL CRICKET SOUNDS ASSESSING THE PERCEPTUAL RELEVANCE OF IDIOSYNCRATIC PARAMETERS
- Log in to post comments
Cricket sounds are usually regarded as pleasant and, thus, can be used as suitable test signals in psychoacoustic experiments assessing the human listening acuity to specific temporal and spectral features. In addition, the simple structure of cricket sounds makes them prone to reverse engineering such that they can be analyzed and re-synthesized with desired alterations in their defining parameters.
poster_AJF.pdf
- Categories:
30 Views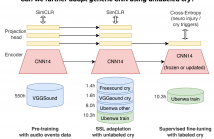
- Read more about Self-supervised learning for infant cry analysis
- Log in to post comments
In this paper, we explore self-supervised learning (SSL) for analyzing a first-of-its-kind database of cry recordings containing clinical indications of more than a thousand newborns. Specifically, we target cry-based detection of neurological injury as well as identification of cry triggers such as pain, hunger, and discomfort.
- Categories:
65 Views
- Read more about END-TO-END ASR-ENHANCED NEURAL NETWORK FOR ALZHEIMER’S DISEASE DIAGNOSIS
- Log in to post comments
This paper presents an approach to Alzheimer’s disease (AD) diagnosis from spontaneous speech using an end-to-end ASR-enhanced neural network. Under the condition that only audio data are provided and accurate transcripts are unavailable, this paper proposes a system that can analyze utterances to differentiate between AD patients, healthy controls, and individuals with mild cognitive impairment. The ASR-enhanced model comprises automatic speech recognition (ASR) with an encoder-decoder structure and the encoder followed by an AD classification network.
- Categories:
23 Views
- Read more about THE SECOND DICOVA CHALLENGE: DATASET AND PERFORMANCE ANALYSIS FOR DIAGNOSIS OF COVID-19 USING ACOUSTICS
- Log in to post comments
The Second Diagnosis of COVID-19 using Acoustics (DiCOVA) Challenge aimed at accelerating the research in acoustics based detection of COVID-19, a topic at the intersection of acoustics, signal processing, machine learning, and healthcare. This paper presents the details of the challenge, which was an open call for researchers to analyze a dataset of audio recordings consisting of breathing, cough and speech signals. This data was collected from individuals with and without COVID-19 infection, and the task in the challenge was a two-class classification.
- Categories:
24 Views
- Read more about THE SECOND DICOVA CHALLENGE: DATASET AND PERFORMANCE ANALYSIS FOR DIAGNOSIS OF COVID-19 USING ACOUSTICS
- Log in to post comments
The Second Diagnosis of COVID-19 using Acoustics (DiCOVA) Challenge aimed at accelerating the research in acoustics based detection of COVID-19, a topic at the intersection of acoustics, signal processing, machine learning, and healthcare. This paper presents the details of the challenge, which was an open call for researchers to analyze a dataset of audio recordings consisting of breathing, cough and speech signals. This data was collected from individuals with and without COVID-19 infection, and the task in the challenge was a two-class classification.
- Categories:
22 Views
- Read more about ORCA-PARTY: An Automtatic Killer Whale Sound Type Separation Toolkit Using Deep Learning
- Log in to post comments
Data-driven and machine-based analysis of massive bioacoustic data collections, in particular acoustic regions containing a substantial number of vocalizations events, is essential and extremely valuable to identify recurring vocal paradigms. However, these acoustic sections are usually characterized by a strong incidence of overlapping vocalization events, a major problem severely affecting subsequent human-/machine-based analysis and interpretation.
- Categories:
25 Views