- Read more about VOXTLM: UNIFIED DECODER-ONLY MODELS FOR CONSOLIDATING SPEECH RECOGNITION, SYNTHESIS AND SPEECH, TEXT CONTINUATION TASKS
- Log in to post comments
We propose a decoder-only language model, VoxtLM, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90.
- Categories:
 23 Views
23 Views- Read more about VOXTLM: UNIFIED DECODER-ONLY MODELS FOR CONSOLIDATING SPEECH RECOGNITION, SYNTHESIS AND SPEECH, TEXT CONTINUATION TASKS
- Log in to post comments
We propose a decoder-only language model, VoxtLM, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90.
- Categories:
32 Views- Read more about Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
- Log in to post comments
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.3% on YouTube captioning.
ICASSP2024_slides.pdf
- Categories:
42 Views
- Read more about Towards a World-English Language Model for On-Device Virtual Assistants
- Log in to post comments
Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them. Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English'' NNLM for on-device VAs. In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs and enhance the multi-dialect baselines.
- Categories:
25 Views
- Read more about MULTIPLE REPRESENTATION TRANSFER FROM LARGE LANGUAGE MODELS TO END-TO-END ASR SYSTEMS
- Log in to post comments
Transferring the knowledge of large language models (LLMs) is a promising technique to incorporate linguistic knowledge into end-to-end automatic speech recognition (ASR) systems. However, existing works only transfer a single representation of LLM (e.g. the last layer of pretrained BERT), while the representation of a text is inherently non-unique and can be obtained variously from different layers, contexts and models. In this work, we explore a wide range of techniques to obtain and transfer multiple representations of LLMs into a transducer-based ASR system.
- Categories:
21 Views
- Read more about Zero Resource Code-switched Speech Benchmark Using Speech Utterance Pairs For Multiple Spoken Languages
- Log in to post comments
We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance.
- Categories:
32 Views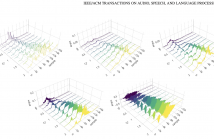
- Read more about Interpreting Intermediate Convolutional Layers of Generative CNNs Trained on Waveforms
- Log in to post comments
This paper presents a technique to interpret and visualize intermediate layers in generative CNNs trained on raw speech data in an unsupervised manner. We argue that averaging over feature maps after ReLU activation in each transpose convolutional layer yields interpretable time-series data. This technique allows for acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information.
- Categories:
52 Views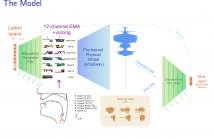
- Read more about Articulation GAN: Unsupervised Modeling of Articulatory Learning
- Log in to post comments
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm, a new unsupervised generative model of speech production/synthesis.
- Categories:
86 Views
- Read more about Integrating multiple ASR systems into NLP backend with attention fusion
- Log in to post comments
- Categories:
33 Views
- Read more about SELF SUPERVISED REPRESENTATION LEARNING WITH DEEP CLUSTERING FOR ACOUSTIC UNIT DISCOVERY FROM RAW SPEECH
- Log in to post comments
The automatic discovery of acoustic sub-word units from raw speech, without any text or labels, is a growing field of research. The key challenge is to derive representations of speech that can be categorized into a small number of phoneme-like units which are speaker invariant and can broadly capture the content variability of speech. In this work, we propose a novel neural network paradigm that uses the deep clustering loss along with the autoregressive con- trastive predictive coding (CPC) loss. Both the loss functions, the CPC and the clustering loss, are self-supervised.
- Categories:
31 Views