
Welcome to ISCSLP 2016 - October 17-20, 2016, Tianjin, China
The ISCSLP will be hosted by Tianjin University. Tianjin has a reputation throughout China for being extremely friendly, safe and a place of delicious food. Welcome to Tianjin to attend the ISCSLP2016. The 10th International Symposium on Chinese Spoken Language Processing (ISCSLP 2016) will be held on October 17-20, 2016 in Tianjin. ISCSLP is a biennial conference for scientists, researchers, and practitioners to report and discuss the latest progress in all theoretical and technological aspects of spoken language processing. While the ISCSLP is focused primarily on Chinese languages, works on other languages that may be applied to Chinese speech and language are also encouraged. The working language of ISCSLP is English.
- Read more about Investigation of the Effects of Automatic Scoring Technology on Human Raters' Performances in L2 Speech Proficiency Assessment
- Log in to post comments
This study investigates how automatic scorings based on speech technology can affect human raters' judgement of students' oral language proficiency in L2 speaking tests. Automatic scorings based on ASR are widely used in non-critical speaking tests or practices and relatively high correlations between machine scores and human scores have been reported. In high-stakes speaking tests, however, many teachers remain skeptical about the fairness of automatic scores given by machines even with the most advanced scoring methods.
- Categories:
 12 Views
12 Views- Read more about Investigation of the Effects of Automatic Scoring Technology on Human Raters' Performances in L2 Speech Proficiency Assessment
- Log in to post comments
This study investigates how automatic scorings based on speech technology can affect human raters' judgement of students' oral language proficiency in L2 speaking tests. Automatic scorings based on ASR are widely used in non-critical speaking tests or practices and relatively high correlations between machine scores and human scores have been reported. In high-stakes speaking tests, however, many teachers remain skeptical about the fairness of automatic scores given by machines even with the most advanced scoring methods.
- Categories:
22 Views- Read more about Rapid Speaker Adaptation Based on D-code Extracted from BLSTM-RNN in LVCSR
- Log in to post comments
Recently, several fast speaker adaptation methods have been proposed for the hybrid DNN-HMM models based on the so called discriminative speaker codes (SC) and applied to unsupervised speaker adaptation in speech recognition. It has been demonstrated that the SC based methods are quite effective in adapting DNNs even when only a very small amount of adaptation data is available. However, in this way we have to estimate speaker code for new speakers by an updating process and obtain the final results through two-pass decoding.
- Categories:
12 Views- Read more about A REGRESSION APPROACH TO BINAURAL SPEECH SEGREGATION VIA DEEP NEURAL NETWORK
- Log in to post comments
This paper proposes a novel regression approach to binaural speech segregation based on deep neural network (DNN). In contrast to the conventional ideal binary mask (IBM) method using DNN with the interaural time difference (ITD) and interaural level difference (ILD) as the auditory features, the log-power spectra (LPS) features of target speech are directly predicted via a regression DNN model by concatenating the monaural LPS features and the binaural features as the input.
- Categories:
6 Views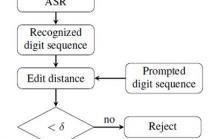
- Read more about Digit-dependent Local I-Vector for Text-Prompted Speaker Verification with
- Log in to post comments
The widely adopted i-vector performances well in textindependent speaker verification with long speech duration.
- Categories:
28 Views- Read more about Exploring Tonal Information for Lhasa Dialect Acoustic Modeling
- Log in to post comments
Detailed analysis of tonal features for Tibetan Lhasa dialect is an important task for Tibetan automatic speech recognition (ASR) applications. However, it is difficult to utilize tonal information because it remains controversial how many tonal patterns the Lhasa dialect has. Therefore, few studies have focused on modeling the tonal information of the Lhasa dialect for speech recognition purpose. For this reason, we investigated influences of the tonal information on the performance of Lhasa Tibetan speech recognition.
- Categories:
13 Views
- Read more about The Design and Implementation of HMM-based Dai Speech Synthesis
- Log in to post comments
By far there are more than 1.2 million Dai compatriots using Dai language in Yunnan province,researching Dai speech synthesis has great significance in advancing the informationization of Dai.This paper researches the implementation of Dai speech synthesis by taking the HMM speech synthesis framework and STRAIGHT synthesizer into account.
In this paper,collection and selection of Dai text corpus,recording of speech corpus,text normalization,segmentation,Romanization and the implementation of acoustic model training are described.
- Categories:
9 Views- Read more about Contributions of the Piriform Fossa of Female Speakers to Vowel Spectra
- Log in to post comments
The bilateral cavities of the piriform fossa are the side branches of the vocal tract and produce anti-resonance(s) in the transfer function. This effect has been known for male vocal tracts, but female data were few. This study investigates contributions of the piriform fossa to vowel spectra in female vocal tracts by means of MRI-based vocal-tract modeling and acoustic experiment with the water-filling technique. Results from three female subjects indicate that the piriform fossa generates one or two dips in the frequency region of 4-6 kHz.
- Categories:
9 Views- Read more about Individual difference and acoustic effect of female laryngeal cavities
- Log in to post comments
This study examines the acoustic effect of the laryngeal cavity of female speakers on the higher vowel spectra. To do so, MRI data of vowels /a/ and /i/ obtained from three female speakers were analyzed with data from a male speaker as reference. 3D vocal-tract shapes were extracted from the MRI data and printed as solid mechanical models. Transfer functions of the models' vocal tracts were estimated by a transmission line model. Individual variations of the laryngeal cavity were described by the area functions of the cavity.
- Categories:
5 Views- Read more about Cognitive Representation of Phonological Categories: The Evidence from Mandarin Speakers’ Learning of Cantonese Tones
- Log in to post comments
- Categories:
6 Views