
Welcome to ISCSLP 2016 - October 17-20, 2016, Tianjin, China
The ISCSLP will be hosted by Tianjin University. Tianjin has a reputation throughout China for being extremely friendly, safe and a place of delicious food. Welcome to Tianjin to attend the ISCSLP2016. The 10th International Symposium on Chinese Spoken Language Processing (ISCSLP 2016) will be held on October 17-20, 2016 in Tianjin. ISCSLP is a biennial conference for scientists, researchers, and practitioners to report and discuss the latest progress in all theoretical and technological aspects of spoken language processing. While the ISCSLP is focused primarily on Chinese languages, works on other languages that may be applied to Chinese speech and language are also encouraged. The working language of ISCSLP is English.
- Read more about Learning FOFE based FNN-LMs with noise contrastive estimation and part-of-speech features
- Log in to post comments
A simple but powerful language model called fixed-size
ordinally-forgetting encoding (FOFE) based feedforward neural
network language models (FNN-LMs) has been proposed recently.
Experimental results have shown that FOFE based FNNLMs
can outperform not only the standard FNN-LMs but also
the popular recurrent neural network language models (RNNLMs).
In this paper, we extend FOFE based FNN-LMs from
several aspects. Firstly, we have proposed a new method to
further improve the performance of FOFE based FNN-LMs by
- Categories:
 20 Views
20 Views- Read more about End-to-end Keywords Spotting Based on Connectionist Temporal Classification for Mandarin
- Log in to post comments
Traditional hybrid DNN-HMM based ASR system for keywords spotting which models HMM states are not flexible to optimize for a specific language. In this paper, we construct an end-to-end acoustic model based ASR for keywords spotting in Mandarin. This model is constructed by LSTM-RNN and trained with objective measure of connectionist temporal classification. The input of the network is feature sequences, and the output the probabilities of the initials and finals of Mandarin syllables.
- Categories:
38 Views- Read more about Detection of Mood Disorder Using Speech Emotion Profiles and LSTM
- Log in to post comments
In mood disorder diagnosis, bipolar disorder (BD) patients are often misdiagnosed as unipolar depression (UD) on initial presentation. It is crucial to establish an accurate distinction between BD and UD to make a correct and early diagnosis, leading to improvements in treatment and course of illness. To deal with this misdiagnosis problem, in this study, we experimented on eliciting subjects’ emotions by watching six eliciting emotional video clips. After watching each video clips, their speech responses were collected when they were interviewing with a clinician.
- Categories:
74 Views

- Read more about Rich Punctuations Prediction Using Large-scale Deep Learning
- Log in to post comments
Punctuation plays an important role in language processing. However, automatic speech recognition systems only output plain word sequences. It is then of interest to predict punctuations on plain word sequences. Previous works have focused on using lexical features or prosodic cues captured from small corpus to predict simple punctuations. Compared with simple punctuations, rich punctuations provide more meaningful
- Categories:
27 Views- Read more about The Correlation Between Signal Distance and Consonant Pronunciation in Mandarin Words
- Log in to post comments
In Mandarin language speaking, some consonant and vowel pairs are hard to be distinguished and pronounced clearly even for some native speakers. This study investigates the signal distance between consonants compared in pairs from the signal processing point of view to reveal the correlation of signal distance and consonant pronunciation. Some popular speech quality objective measures are innovatively applied to obtain the signal distance.
- Categories:
8 Views- Read more about A study of variational method for text-independent speaker recognition
- Log in to post comments
An i-vector has become the state-of-the-art algorithm for text-independent recognition. Most of related works take the extraction of the i-vector as a black-box by using some open software (e.g. Kaldi, Alize) and focus on the vector-based back-end algorithms, such as length normalization, WCCN, or PLDA. In this paper, we study the variational method and present a concise derivation for the i-vector. Based on our proposed methods, three criteria for derivation are compared. There are maximum likelihood (ML), maximum a posteriori (MAP) and maximum
- Categories:
10 Views
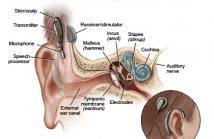
- Read more about The effect of gain thresholds on speech intelligibility for statistical model based noise reduction for cochlear implants:A simulation based verification
- Log in to post comments
Noise corruption can dramatically decrease the speech intelligibility for listeners with cochlear implants (CI). Noise reduction is a key point in CI speech processing strategy. This paper proposes a statistical model based noise reduction algorithm forCIs. A realistic noise estimator, which requires no prior knowledge of the noise, is adopted for noise estimation.
- Categories:
17 Views
- Read more about Classification between normal and adventitious lung sounds using deep neural network
- Log in to post comments
- Categories:
22 Views