
- Read more about ICIP2025_Supplementary_ESCANet
- Log in to post comments
While deep learning based solutions, including CNNs or transformer-based architectures, have demonstrated promising results for image super-resolution (SR) tasks, their substantial depth and parameters challenge deployment on edge computing AI-enabled devices. To address this issue, we propose a lightweight single image super-resolution (SISR) model named Efficient Spatial and Channel Attentive Network (ESCANet), comprised of Spatial Enhancement Module (SEM) and Channel-wise Enhancement Module (CEM).
- Categories:
 52 Views
52 Views- Read more about A UNIFIED DNN-BASED SYSTEM FOR INDUSTRIAL PIPELINE SEGMENTATION
- Log in to post comments
This paper presents a unified system tailored for autonomous pipe segmentation within an industrial setting. To this end, it is designed to analyze RGB images captured by Unmanned Aerial Vehicle (UAV)-mounted cameras to predict binary pipe segmentation maps.
- Categories:
42 Views
We address distinguishing whether an input is a facial image by learning only a facial-expression recognition (FER) dataset.
- Categories:
66 Views
We address distinguishing whether an input is a facial image by learning only a facial-expression recognition (FER) dataset.
- Categories:
33 Views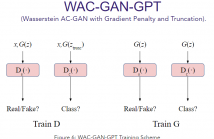
- Read more about Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
- Log in to post comments
Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes.
- Categories:
55 Views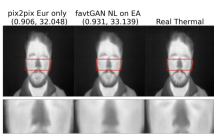
- Read more about GENERATING THERMAL HUMAN FACES FOR PHYSIOLOGICAL ASSESSMENT. USING THERMAL SENSOR AUXILIARY LABELS
- Log in to post comments
Thermal images reveal medically important physiological information about human stress, signs of inflammation, and emotional mood that cannot be seen on visible images. Providing a method to generate thermal faces from visible images would be highly valuable for the telemedicine community in order to show this medical information. To the best of our knowledge, there are limited works on visible-to-thermal (VT) face translation, and many current works go the opposite direction to generate visible faces from thermal surveillance images (TV) for law enforcement applications.
- Categories:
15 Views
- Read more about WSO-CAPS: An Automated Framework for Diagnosis of COVID-19 disease from Low and Ultra-Low Dose CT scans using Capsule Networks and Window Setting Optimization
- Log in to post comments
The automatic diagnosis of lung infections using chest computed
tomography (CT) scans has been recently obtained remarkable significance,
particularly during the COVID-19 pandemic that the early
diagnosis of the disease is of utmost importance. In addition, infection
diagnosis is the main building block of most automated diagnostic/
prognostic frameworks. Recently, due to the devastating effects
of the radiation on the body caused by the CT scan, there has been
a surge in acquiring low and ultra-low-dose CT scans instead of the
- Categories:
20 Views
- Read more about GLAUCOMA DETECTION FROM RAW CIRCUMPAPILLARY OCT IMAGES USING FULLY CONVOLUTIONAL NEURAL NETWORKS
- Log in to post comments
- Categories:
35 Views
- Read more about CONTEXT-AWARE AUTOMATIC OCCLUSION REMOVAL
- Log in to post comments
Occlusion removal is an interesting application of image enhancement, for which, existing work suggests manually-annotated or domain-specific occlusion removal. No work tries to address automatic occlusion detection and removal as a context-aware generic problem. In this paper, we present a novel methodology to identify objects that do not relate to the image context as occlusions and remove them, reconstructing the space occupied coherently.
- Categories:
17 Views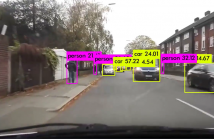
This paper proposed a modified YOLOv3 which has an extra object depth prediction module for obstacle detection and avoidance. We use a pre-processed KITTI dataset to train the proposed, unified model for (i) object detection and (ii) depth prediction and use the AirSim flight simulator to generate synthetic aerial images to verify that our model can be applied in different data domains.
- Categories:
325 Views