- Read more about Poster: Synchformer: Efficient Synchronization from Sparse Cues
- Log in to post comments
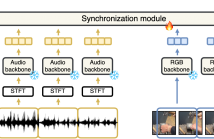
Our objective is audio-visual synchronization with a focus on ‘in-the-wild’ videos, such as those on YouTube, where synchronization cues can be sparse. Our contributions include a novel audio-visual synchronization model, and training that decouples feature extraction from synchronization modelling through multi-modal segment-level contrastive pre-training. This approach achieves state-of-the-art performance in both dense and sparse settings.
vi_poster.pdf
- Categories:
 49 Views
49 Views
- Read more about Multimodal Depression Classification Using Articulatory Coordination Features and Hierarchical Attention Based Text Embeddings
- Log in to post comments
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to unimodal classifiers (7.5% and 13.7% for audio and text respectively).
3649_poster.pdf
- Categories:
35 Views
- Read more about Audio-Visual Speech Inpainting with Deep Learning
- Log in to post comments
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e. the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and they generally aim at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration.
- Categories:
15 Views
- Read more about Audio-Visual Speech Inpainting with Deep Learning
- Log in to post comments
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e. the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and they generally aim at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration.
- Categories:
22 Views