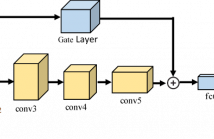
- Read more about Gate connected Convolutional Neural Network for Object Tracking
- Log in to post comments
Convolutional neural networks (CNNs) have been employed in visual tracking due to their rich levels of feature representation. While the learning capability of a CNN increases with its depth, unfortunately spatial information is diluted in deeper layers which hinders its important ability to localise targets. To successfully manage this trade-off, we propose a novel residual network based gating CNN architecture for object tracking. Our deep model connects the front and bottom convolutional features with a gate layer.
- Categories:
 22 Views
22 Views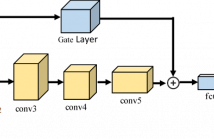
- Read more about Gate connected Convolutional Neural Network for Object Tracking
- Log in to post comments
Convolutional neural networks (CNNs) have been employed in visual tracking due to their rich levels of feature representation. While the learning capability of a CNN increases with its depth, unfortunately spatial information is diluted in deeper layers which hinders its important ability to localise targets. To successfully manage this trade-off, we propose a novel residual network based gating CNN architecture for object tracking. Our deep model connects the front and bottom convolutional features with a gate layer.
poster_ICIP.pdf
- Categories:
14 Views- Read more about Interactive Fault Extraction in 3D Seismic Data Using the Hough Transform and Tracking Vectors
- Log in to post comments
The exploration of reservoir regions has a close relationship with the localization of faults. Although faults can be labeled in seismic volumes by experienced interpreters, such manual interpretation is inefficient when dealing with a dramatically growing amount of collected seismic data. To speed up the interpretation efficiency of faults, in this paper, we propose a method that semi-automatically detects fault surfaces using the Hough transform as well as tracking vectors.
- Categories:
61 Views- Read more about MULTI-OBJECT TRACKING BY VIRTUAL NODES ADDED MIN-COST NETWORK FLOW
- Log in to post comments
- Categories:
19 Views
- Read more about DEEP DECOMPOSITION OF CIRCULARLY SYMMETRIC GABOR WAVELET FOR ROTATION-INVARIANT TEXTURE IMAGE CLASSIFICATION
- Log in to post comments
We propose Deep Decomposition of Circularly Symmetric Gabor Wavelet (DD-CSGW) for rotation-invariant texture image classification. Circularly Symmetric Gabor Wavelet (CSGW) is rotation-invariant tool for image analysis. However, CSGW has an obvious shortcoming: it extracts less discriminative information from image due to lack of directional selectivity.
- Categories:
11 Views- Read more about ICIP 2017 Paper #2679: THE DIVISIVE NORMALIZATION TRANSFORM BASED REDUCED-REFERENCE IMAGE QUALITY ASSESSMENT IN THE SHEARLET DOMAIN
- Log in to post comments
Reduced-reference (RR) image quality assessment (IQA)metric aims to employ less partial information about the original reference image to achieve higher evaluation accuracy. In this paper, we propose a novel RRIQA metric based on the divisive normalization transform (DNT) in the discrete nonseparable shearlet transform (DNST) domain.
- Categories:
17 Views- Read more about Joint Tracking and Gait Recognition of Multiple People in Video
- Log in to post comments
We propose a novel approach to address the problem of jointly tracking and gait recognition of multiple people in a video sequence. The most state of the art algorithms for gait recognition consider the cases where there is only one person without any occlusion in a very constrained environment. However, in real scenarios such as in airports, train stations, etc, there are many people in the environment that make these algorithms inapplicable.
- Categories:
17 Views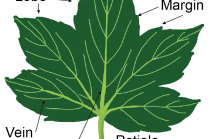
We introduce a new reference axis for leaf classification. The new reference axis, called a Mid-Leaf axis, is based on a quadratic curve that lies on the middle of a leaf. This curve is derived from three basic landmark points: an apex, a centroid, and a petiole. After mapping to a new plane based on this curve, leaf shape features are invariant under translation, rotation, scaling, and bending. We propose the leaf shape features based on partitioning the morphological features and the tangent’s direction angle of the leaf contour.
- Categories:
69 Views- Read more about Integrated Deep and Shallow Networks for Salient Object Detection
- Log in to post comments
icip-ppt.pdf
- Categories:
12 Views- Read more about HYBRID SALIENT MOTION DETECTION USING TEMPORAL DIFFERENCING AND KALMAN FILTER TRACKING WITH NON-STATIONARY CAMERA
- Log in to post comments
Uncertain motion of typical surveillance targets, e.g. slow moving or stopped, abrupt acceleration, and uniform motion makes a single salient motion detection algorithm unsuitable for accurate segmentation. It becomes even more challenging in case of the camera is non-stationary. In this paper, first, a simple local adaptive temporal differencing method is proposed to detect moving objects boundaries and partial interiors.
- Categories:
6 Views