- Read more about Aicyber’s System for IALP 2016 Shared Task:Character-enhanced Word Vectors and Boosted Neural Networks
- Log in to post comments
- Categories:
 20 Views
20 Views
- Read more about Recurrent Neural Network-based Language Models with Variation in Net Topology, Language, and Granularity
- Log in to post comments
In this paper, we study language models based on recurrent neural networks on three databases in two languages. We implement basic recurrent neural networks (RNN) and refined RNNs with long short-term memory (LSTM) cells. We use the corpora of Penn Tree Bank (PTB) and AMI in English, and the Academia Sinica Balanced Corpus (ASBC) in Chinese. On ASBC, we investigate wordbased and character-based language models. For characterbased language models, we look into the cases where the inter-word space is treated or not treated as a token.
40_RNN.pdf
- Categories:
21 Views
It has been argued that recurrent neural network language models are better in capturing long-range dependency than n-gram language models. In this paper, we attempt to verify this claim by investigating the prediction accuracy and the perplexity of these language models as a function of word position, i.e., the position of a word in a sentence. It is expected that as word position increases, the advantage of using recurrent neural network language models over n-gram language models will become more and more evident.
- Categories:
21 Views- Read more about History Question Classification and Representation for Chinese Gaokao
- Log in to post comments
In this paper, we propose a question representation based on entity labeling and question classification for a automatic question answering system of Chinese Gaokao history question. A CRF model is used for the entity labeling and SVM/CNN/LSTM models are tested for question classification. Our experiments show that CRF model provides a high performance when used to label informative entities out while neural networks has a promising performance for the question classification task.
- Categories:
34 Views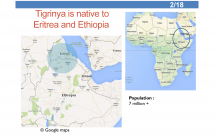
- Read more about The Effect of Shallow Segmentation for English-Tigrinya Statistical Machine Translation
- Log in to post comments
This paper presents initial English-Tigrinya statistical machine translation (SMT) research. Tigrinya is a highly inflected Semitic language spoken in Eritrea and Ethiopia. Translation involving morphologically complex languages is challenged by factors including data sparseness and source-target word alignment. We try to address these problems through morphological segmentation of Tigrinya words. After segmentation the difference in token count dropped significantly from 37.7% to 0.1%. The out-of-vocabulary rate was reduced by 46%.
IALP-tig.pdf
- Categories:
47 Views
We present a word sense disambiguation (WSD) tool of Japanese Hiragana words. Unlike other WSD tasks which output something like “sense #3” as result, our WSD task rewrites the target word into a Kanji word, which is a different orthography. This means that the task is also a kind of orthographical normalization as well as WSD. In this paper we present the task, our method, and the performance.
IALP-wsd.pdf
- Categories:
22 Views- Read more about Detecting Representative Web Articles Using Heterogeneous Graphs
- Log in to post comments
- Categories:
13 Views- Read more about Annotation Schemes for Constructing Uyghur Named Entity Relation Corpus
- Log in to post comments
Uyghur is minority language in China, it is one of the official languages in Xinjiang Uyghur Autonomous Region of China. More than 10 million people use Uyghur in their daily life and even on the Internet. However, lack of Uyghur entity relation corpus constrains relation extraction applications in Uyghur. In this paper, we describe annotation schemes for creating annotated corpus for Uyghur named entity and Uyghur named entity relation.
- Categories:
26 Views
- Read more about Construction of the Basic Sentence-pattern Instance Database Based on the International Chinese Textbook Treebank
- Log in to post comments
- Categories:
6 Views- Read more about Japanese Orthographical Normalization Does Not Work for Statistical Machine Translation
- Log in to post comments
We have investigated the effect of normalizing Japanese orthographical variants into a uniform orthography on statistical machine translation (SMT) between Japanese and English. In Japanese, 10% of words have reportedly more than one orthographical variants, which is a promising fact for improving translation quality when we normalize these orthographical variants.
- Categories:
3 Views