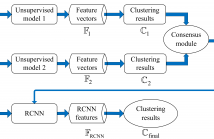
- Read more about PSEUDO-SUPERVISED APPROACH FOR TEXT CLUSTERING BASED ON CONSENSUS ANALYSIS
- Log in to post comments
In recent years, neural networks (NN) have achieved remarkable performance improvement in text classification due to
their powerful ability to encode discriminative features by incorporating label information into model training. Inspired
by the success of NN in text classification, we propose a pseudo-supervised neural network approach for text clustering.
The neural network is trained in a supervised fashion with pseudo-labels, which are provided by the cluster labels
- Categories:
 8 Views
8 Views
- Read more about Improving Semi-Supervised Classification for Low-Resource Speech Interaction Applications
- Log in to post comments
We propose a semi-supervised learning method to improve classification performance in scenarios with limited labeled
data. We employ adaptation strategies such as entropy-filtering and self-training, and show that our method achieves
- Categories:
73 Views
- Read more about CONVOLUTIONAL NEURAL NETWORKS AND MULTITASK STRATEGIES FOR SEMANTIC MAPPING OF NATURAL LANGUAGE INPUT TO A STRUCTURED DATABASE
- Log in to post comments
In this work, we investigate mapping both natural language food and quantity descriptions to matching USDA database entries. We demonstrate that a convolutional neural network (CNN) model with a softmax layer on top to directly predict the most likely database matches outperforms our previous state-of-the-art approach of learning binary classification and subsequently ranking database entries using similarity scores with the learned embeddings.
- Categories:
12 Views- Read more about Semantic Mapping of Natural Language Input to Database Entries via Convolutional Neural Networks
- Log in to post comments
Natural language processing research has made major advances with the concept of representing words, sentences, paragraphs, and even documents by embedded vector representations. We apply this idea to the problem of relating foods, as expressed in natural language meal descriptions, to corresponding database entries. We generate fixed-length embeddings for U.S.
icassp_17.pdf
- Categories:
13 Views
- Read more about THE SHEFFIELD SEARCH AND RESCUE CORPUS
- Log in to post comments
As part of an ongoing research into extracting mission-critical information from Search and Rescue speech communications, a corpus of unscripted, goal-oriented, two-party spoken conversations has been designed and collected. The Sheffield Search and Rescue (SSAR) corpus comprises about 12 hours of data from 96 conversations by 24 native speakers of British English with a southern accent. Each conversation is about a collaborative task of exploring and estimating a simulated indoor environment.
- Categories:
8 Views
- Read more about EEG Evidence for a Three-Phase Recurrent Process during Spoken Word Processing
- Log in to post comments
- Categories:
23 Views- Read more about Dialog State Tracking for Interview Coaching Using Two-Level LSTM
- Log in to post comments
This study presents an approach to dialog state tracking (DST) in an interview conversation by using the long short-term memory (LSTM) and artificial neural network (ANN). First, the techniques of word embedding are employed for word representation by using the word2vec model. Then, each input sentence is represented by a sentence hidden vector using the LSTM-based sentence model. The sentence hidden vectors for each sentence are fed to the LSTM-based answer model to map the interviewee’s answer to an answer hidden vector.
- Categories:
7 Views- Read more about Dialog State Tracking for Interview Coaching Using Two-Level LSTM
- Log in to post comments
This study presents an approach to dialog state tracking (DST) in an interview conversation by using the long short-term memory (LSTM) and artificial neural network (ANN). First, the techniques of word embedding are employed for word representation by using the word2vec model. Then, each input sentence is represented by a sentence hidden vector using the LSTM-based sentence model. The sentence hidden vectors for each sentence are fed to the LSTM-based answer model to map the interviewee’s answer to an answer hidden vector.
- Categories:
9 Views
- Read more about Poster for Unsupervised User Intent Modeling by Feature-Enriched Matrix Factorization
- Log in to post comments
Spoken language interfaces are being incorporated into various devices such as smart phones and TVs. However, dialogue systems may fail to respond correctly when users’ request functionality is not supported by currently installed apps. This paper proposes a feature-enriched matrix factorization (MF) approach to model open domain intents, which allows a system to dynamically add unexplored domains according to users’ requests.
- Categories:
27 Views