
DCC 2022 Conference - The Data Compression Conference (DCC) is an international forum for current work on data compression and related applications. Both theoretical and experimental work are of interest. Visit the DCC 2022 website.

- Read more about FM-Indexing Grammars Induced by Suffix Sorting for Long Patterns
- Log in to post comments
- Categories:
 62 Views
62 Views- Read more about Orthonormal Matrix Codebook Design for Adaptive Transform Coding
- Log in to post comments
A novel algorithm for designing optimized orthonormal transform-matrix codebooks for adaptive transform coding of a non-stationary vector process is proposed. This algorithm relies on a block-wise stationary model of a non-stationary process and finds a codebook of transform-matrices by minimizing the end-to-end mean square error of transform coding averaged over the distribution of stationary blocks of vectors.
- Categories:
43 Views
- Read more about Learning-Based Fast Depth Inter Coding for 3D-HEVC via XGBoost
- Log in to post comments
The 3D extension of High Efficiency Video Coding (3D-HEVC) achieves excellent performance for 3D video coding while possessing significant computational complexity. To accelerate the time-consuming coding process of the depth map, a fast algorithm via XGBoost is proposed in this paper. Specifically, a total of 14 specialized XGBoost models are used for different block sizes and viewpoint types to achieve early coding unit partition determination (ECP) and early prediction unit mode selection (EPM) to avoid executing the exhaustive traversal coding process.
- Categories:
95 Views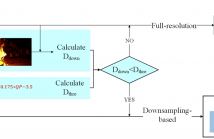
Resampling-based coding, i.e. down-sampling before encoding and up-sampling after decoding, has been recognized to be an effective tool for compressing high-resolution videos at low bitrates. The newest video coding standard, Versatile Video Coding (VVC), supports resampling-based coding via a mechanism named Reference Picture Resampling (RPR), where the spatial resolution can be changed without inserting an intra frame. Intuitively, it is not wise to utilize a single resolution throughout the whole video, because frames with different contents may prefer different coding resolutions.
- Categories:
272 Views
- Read more about SAQENet: A Quality Enhancement Network for Compressed Video with Self-attention
- Log in to post comments
- Categories:
16 Views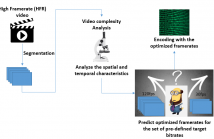
- Read more about CODA: Content-aware Frame Dropping Algorithm for High Frame-rate Video Streaming
- Log in to post comments
High Framerate (HFR) video streaming enhances the viewing experience and improves visual clarity. However, it may lead to an increase of both encoding time complexity and compression artifacts at lower bitrates. To address this challenge, this paper proposes a content-aware frame dropping algorithm (CODA) to drop frames uniformly in every video (segment) according to the target bitrate and the video characteristics.
- Categories:
128 Views
- Read more about RNNSC: Recurrent Neural Network Based Stereo Compression Using Image and State Warping
- Log in to post comments
- Categories:
36 Views
- Read more about Succinct Data Structure for Path Graphs
- Log in to post comments
We consider the problem of designing space-efficient data structures for unlabelled path graphs with n vertices while supporting basic navigational queries such as degree, adjacency, and neighborhood queries efficiently. We provide two solutions for this problem. Our first data structure is succinct and occupies n log n+o(n log n) bits while answering adjacency query in O(log n) time, and neighborhood and degree queries in O(d log^2 n) time where d is the degree of the queried vertex. Our second data structure answers all these queries faster at the expense of slightly more space.
- Categories:
40 Views