
- Read more about ENACT: Entropy-based Clustering of Attention Input for Reducing the Computational Resources of Object Detection Transformers - Supplementary Material
- Log in to post comments
Transformers demonstrate competitive performance in terms of precision on the problem of vision-based object detection. However, they require considerable computational resources due to the quadratic size of the attention weights.
- Categories:
 48 Views
48 Views
- Read more about A Multichannel Localization Method for Camouflaged Object Detection
- Log in to post comments
This paper proposes a multichannel method for discriminative region localization in Camouflaged Object Detection (COD) tasks. In one channel, processing the phase and amplitude of 2-D Fourier spectra generate a modified form of the original image, used later for a pixel-wise optimal local entropy analysis. The other channel implements a class activation map (CAM) and Global Average Pooling (GAP) for object localization. We combine the channels linearly to form the final localized version of the COD images.
- Categories:
106 Views
- Read more about A Multichannel Localization Method for Camouflaged Object Detection
- Log in to post comments
This paper proposes a multichannel method for discriminative region localization in Camouflaged Object Detection (COD) tasks. In one channel, processing the phase and amplitude of 2-D Fourier spectra generate a modified form of the original image, used later for a pixel-wise optimal local entropy analysis. The other channel implements a class activation map (CAM) and Global Average Pooling (GAP) for object localization. We combine the channels linearly to form the final localized version of the COD images.
- Categories:
21 Views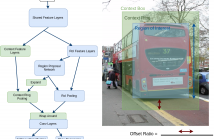
- Read more about IMPROVING PROPOSAL-BASED OBJECT DETECTION USING CONVOLUTIONAL CONTEXT FEATURES
- Log in to post comments
A novel extension to proposal-based detection is proposed in order to learn convolutional context features for determining boundaries of objects better. Objects and their context are aimed to be learned through parallel convolutional stages. The resulting object and context feature maps are combined in such a way that they preserve their spatial relationship. The proposed algorithm is trained and evaluated on PASCAL VOC 2007 detection benchmark dataset and yielded improvements in performance over baseline, for all classes, especially the ones with distinctive context.
- Categories:
43 Views- Read more about Saliency Guided Wavelet Compression for Low-Bitrate Image and Video Coding
- Log in to post comments
We propose an improved saliency guided wavelet
compression scheme for low-bitrate image/video coding applications.
Important regions (faces in security camera feeds,
vehicles in traffic surveillance) get degraded significantly at low
bitrates by existing compression standards, such as JPEG/JPEG-
2000/MPEG-4, since these do not explicitly utilize any knowledge
of which regions are salient. We design a compression algorithm
which, given an image/video and a saliency value for each
- Categories:
23 Views