
- Read more about Modeling Melodic Feature Dependency with Modularized Variational Auto-Encoder
- Log in to post comments
Automatic melody generation has been a long-time aspiration for both AI researchers and musicians. However, learning to generate euphonious melodies has turned out to be highly challenging. This paper introduces 1) a new variant of variational autoencoder (VAE), where the model structure is designed in a modularized manner in order to model polyphonic and dynamic music with domain knowledge, and 2) a hierarchical encoding/decoding strategy, which explicitly models the dependency between melodic features.
- Categories:
 22 Views
22 Views
- Read more about Intonation: a Dataset of Quality Vocal Performances Refined by Spectral Clustering on Pitch Congruence
- Log in to post comments
We introduce the "Intonation" dataset of amateur vocal performances with a tendency for good intonation, collected from Smule, Inc. The dataset can be used for music information retrieval tasks such as autotuning, query by humming, and singing style analysis. It is available upon request on the Stanford CCRMA DAMP website. We describe a semi-supervised approach to selecting the audio recordings from a larger collection of performances based on intonation patterns.
- Categories:
60 Views
- Read more about ENHANCING MUSIC FEATURES BY KNOWLEDGE TRANSFER FROM USER-ITEM LOG DATA
- Log in to post comments
- Categories:
13 Views
- Read more about Modeling nonlinear audio effects with end-to-end deep neural networks
- Log in to post comments
Audio processors whose parameters are modified periodically
over time are often referred as time-varying or modulation based
audio effects. Most existing methods for modeling these type of
effect units are often optimized to a very specific circuit and cannot
be efficiently generalized to other time-varying effects. Based on
convolutional and recurrent neural networks, we propose a deep
learning architecture for generic black-box modeling of audio processors
with long-term memory. We explore the capabilities of
- Categories:
55 Views
In the recent years, singing voice separation systems showed increased performance due to the use of supervised training. The design of training datasets is known as a crucial factor in the performance of such systems. We investigate on how the characteristics of the training dataset impacts the separation performances of state-of-the-art singing voice separation algorithms. We show that the separation quality and diversity are two important and complementary assets of a good training dataset. We also provide insights on possible transforms to perform data augmentation for this task.
- Categories:
53 Views
- Read more about CNN Based Two-Stage Multi-Resolution End-to-End Model for Singing Melody Extraction
- Log in to post comments
Inspired by human hearing perception, we propose a twostage multi-resolution end-to-end model for singing melody extraction in this paper. The convolutional neural network (CNN) is the core of the proposed model to generate multiresolution representations. The 1-D and 2-D multi-resolution analysis on waveform and spectrogram-like graph are successively carried out by using 1-D and 2-D CNN kernels of different lengths and sizes.
- Categories:
33 Views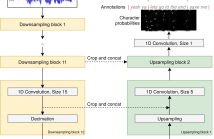
- Read more about End-to-End Lyrics Alignment Using An Audio-to-Character Recognition Model
- Log in to post comments
Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form.
- Categories:
221 Views
- Read more about DEEP POLYPHONIC ADSR PIANO NOTE TRANSCRIPTION
- Log in to post comments
- Categories:
71 Views
- Read more about Deep Learning for Tube Amplifier Emulation
- Log in to post comments
Analog audio effects and synthesizers often owe their distinct sound to circuit nonlinearities. Faithfully modeling such significant aspect of the original sound in virtual analog software can prove challenging. The current work proposes a generic data-driven approach to virtual analog modeling and applies it to the Fender Bassman 56F-A vacuum-tube amplifier. Specifically, a feedforward variant of the WaveNet deep neural network is trained to carry out a regression on audio waveform samples from input to output of a SPICE model of the tube amplifier.
- Categories:
30 Views
- Read more about Evaluating Salience Representations for Cross-Modal Retrieval of Western Classical Music Recordings
- Log in to post comments
In this contribution, we consider a cross-modal retrieval scenario of Western classical music. Given a short monophonic musical theme in symbolic notation as query, the objective is to find relevant audio recordings in a database. A major challenge of this retrieval task is the possible difference in the degree of polyphony between the monophonic query and the music recordings. Previous studies for popular music addressed this issue by performing the cross-modal comparison based on predominant melodies extracted from the recordings.
- Categories:
77 Views