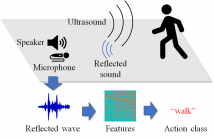
- Read more about HEAR-YOUR-ACTION: HUMAN ACTION RECOGNITION BY ULTRASOUND ACTIVE SENSING
- Log in to post comments
Action recognition is a key technology for many industrial applications. Methods using visual information such as images are very popular. However, privacy issues prevent widespread usage due to the inclusion of private information, such as visible faces and scene backgrounds, which are not necessary for recognizing user action. In this paper, we propose a privacy-preserving action recognition by ultrasound active sensing.
- Categories:
 55 Views
55 Views
- Read more about Jazznet: A Dataset of Fundamental Piano Patterns for Music Audio Machine Learning Research
- Log in to post comments
The paper introduces the jazznet Dataset, a dataset of fundamental jazz piano music patterns for developing machine learning (ML) algorithms in music information retrieval (MIR). The dataset contains 162520 labeled piano patterns, including chords, arpeggios, scales, and chord progressions with their inversions, resulting in more than 26k hours of audio and a total size of 95GB.
jazznetPoster.pdf
- Categories:
35 Views
- Read more about Chord-Conditioned Melody Harmonization with Controllable Harmonicity
- Log in to post comments
Melody harmonization has long been closely associated with chorales composed by Johann Sebastian Bach. Previous works rarely emphasised chorale generation conditioned on chord progressions, and there has been a lack of focus on assistive compositional tools. In this paper, we first designed a music representation that encoded chord symbols for chord conditioning, and then proposed DeepChoir, a melody harmonization system that can generate a four-part chorale for a given melody conditioned on a chord progression.
- Categories:
12 Views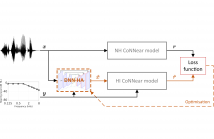
- Read more about DNN-HA: A DNN-based hearing-aid strategy for real-time processing
- Log in to post comments
Although hearing aids (HAs) can compensate for elevated hearing thresholds using sound amplification, they often fail to restore auditory perception in adverse listening conditions. Here, we present a deep-neural-network (DNN) HA processing strategy that can provide individualised sound processing for the audiogram of a listener using a single model architecture. Our multi-purpose HA model can be used for different individuals and can process audio inputs of 3.2 ms in <0.5 ms, thus paving the way for precise DNN-based treatments of hearing loss that can be embedded in hearing devices.
- Categories:
59 Views
- Read more about HYBRID ATTENTION-BASED PROTOTYPICAL NETWORKS FOR FEW-SHOT SOUND CLASSIFICATION
- Log in to post comments
In recent years, prototypical networks have been widely used
in many few-shot learning scenarios. However, as a metric-
based learning method, their performance often degrades in
the presence of bad or noisy embedded features, and outliers
in support instances. In this paper, we introduce a hybrid at-
tention module and combine it with prototypical networks for
few-shot sound classification. This hybrid attention module
consists of two blocks: a feature-level attention block, and
- Categories:
71 Views
- Read more about L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
- Log in to post comments
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition1. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model’s efficiency and overcome the major difficulties encountered by the participants of the previous challenge.
- Categories:
14 Views
- Read more about Improving Feature Generalizability With Multitask Learning In Class Incremental Learning
- Log in to post comments
- Categories:
70 Views
- Read more about Improving Feature Generalizability With Multitask Learning In Class Incremental Learning
- Log in to post comments
- Categories:
10 Views
- Read more about Poster - KARASINGER: SCORE-FREE SINGING VOICE SYNTHESIS WITH VQ-VAE USING MEL-SPECTROGRAMS
- Log in to post comments
- Categories:
13 Views
- Read more about Slides - KARASINGER: SCORE-FREE SINGING VOICE SYNTHESIS WITH VQ-VAE USING MEL-SPECTROGRAMS
- Log in to post comments
- Categories:
7 Views