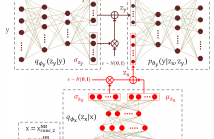
- Read more about LATENT REPRESENTATION LEARNING FOR ARTIFICIAL BANDWIDTH EXTENSION USING A CONDITIONAL VARIATIONAL AUTO-ENCODER
- Log in to post comments
Artificial bandwidth extension (ABE) algorithms can improve speech quality when wideband devices are used with narrowband
ICASSP2019.pdf
- Categories:
 52 Views
52 Views
- Read more about OBJECTIVE COMPARISON OF SPEECH ENHANCEMENT ALGORITHMS WITH HEARING LOSS SIMULATION
- Log in to post comments
Many speech enhancement algorithms have been proposed over the years and it has been shown that deep neural networks can lead to significant improvements. These algorithms, however, have not been validated for hearing-impaired listeners. Additionally, these algorithms are often evaluated under a limited range of signal-to-noise ratios (SNR). Here, we construct a diverse speech dataset with a broad range of SNRs and noises.
- Categories:
60 Views
- Read more about LINEAR PREDICTION-BASED PART-DEFINED AUTO-ENCODER USED FOR SPEECH ENHANCEMENT
- Log in to post comments
This paper proposes a linear prediction-based part-defined auto-encoder (PAE) network to enhance speech signal. The PAE is a defined decoder or an established encoder network, based on an efficient learning algorithm or classical model. In this paper, the PAE utilizes AR-Wiener filter as the decoder part, and the AR-Wiener filter is modified as a linear prediction (LP) model by incorporating the modified factor from the residual signal. The parameters of line spectral frequency (LSF) of speech and noise and the Wiener filtering mask are utilized for training targets.
- Categories:
90 Views
- Read more about TasNet: time-domain audio separation network for real-time, single-channel speech separation
- Log in to post comments
Robust speech processing in multi-talker environments requires effective speech separation. Recent deep learning systems have made significant progress toward solving this problem, yet it remains challenging particularly in real-time, short latency applications. Most methods attempt to construct a mask for each source in time-frequency representation of the mixture signal which is not necessarily an optimal representation for speech separation.
- Categories:
86 Views
- Read more about Speech Dereverberation based on Convex Optimization Algorithms for Group Sparse Linear Prediction
- Log in to post comments
In this paper, we consider methods for improving far-field speech recognition using dereverberation based on sparse multi-channel linear prediction. In particular, we extend successful methods based on nonconvex iteratively reweighted least squares, that look for a sparse desired speech signal in the short-term Fourier transform domain, by proposing sparsity promoting convex functions. Furthermore, we show how to improve performance by applying regularization into both the reweighted least squares and convex methods.
- Categories:
57 Views
- Read more about TIME-FREQUENCY MASKING-BASED SPEECH ENHANCEMENT USING GENERATIVE ADVERSARIAL NETWORK
- Log in to post comments
- Categories:
88 Views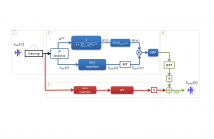
- Read more about EFFICIENT SUPER-WIDE BANDWIDTH EXTENSION USING LINEAR PREDICTION BASED ANALYSIS-SYNTHESIS
- Log in to post comments
Many smart devices now support high-quality speech communication services at super-wide bandwidths. Often, however, speech quality is degraded when they are used with networks or devices which lack super-wideband support. Artificial bandwidth extension can then be used to improve speech quality. While approaches to wideband extension have been reported previously, this paper proposes an approach to super-wide bandwidth extension.
- Categories:
47 Views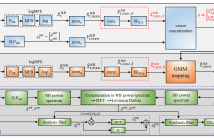
- Read more about EXPLOITING EXPLICIT MEMORY INCLUSION FOR ARTIFICIAL BANDWIDTH EXTENSION
- Log in to post comments
Artificial bandwidth extension (ABE) algorithms have been developed to improve speech quality when wideband devices are used in conjunction with narrowband devices or infrastructure. While past work points to the benefit of using contextual information or memory for ABE, an understanding of the relative benefit of explicit memory inclusion, rather than just dynamic information, calls for a comparative, quantitative analysis. The need for practical ABE solutions calls further for the inclusion of memory without significant increases to latency or computational complexity.
- Categories:
17 Views- Read more about ICA BASED SINGLE MICROPHONE BLIND SPEECH SEPARATION TECHNIQUE USING NON-LINEAR ESTIMATION OF SPEECH
- Log in to post comments
In this paper, a Blind Speech Separation (BSS) technique is introduced based on Independent Component Analysis (ICA) for underdetermined single microphone case. In general, ICA uses noisy speech from at least two microphones to separate speech and noise. But ICA fails to separate when only one stream of noisy speech is available. We use Log Spectral Magnitude Estimator based on Minimum Mean Square Error (LogMMSE) as a non-linear estimation technique to estimate the speech spectrum, which is used as the other input to ICA, with the noisy speech.
- Categories:
44 Views