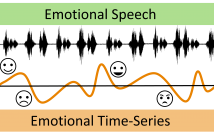
- Read more about Dynamic Speech Emotion Recognition using a Conditional Neural Process
- Log in to post comments
The problem of predicting emotional attributes from speech has often focused on predicting a single value from a sentence or short speaking turn. These methods often ignore that natural emotions are both dynamic and dependent on context. To model the dynamic nature of emotions, we can treat the prediction of emotion from speech as a time-series problem. We refer to the problem of predicting these emotional traces as dynamic speech emotion recognition. Previous studies in this area have used models that treat all emotional traces as coming from the same underlying distribution.
- Categories:
 115 Views
115 Views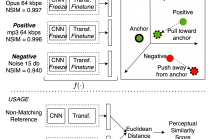
- Read more about NOMAD: Non-Matching Audio Distance
- Log in to post comments
This paper presents NOMAD (Non-Matching Audio Distance), a differentiable perceptual similarity metric that measures the distance of a degraded signal against non-matching references. The proposed method is based on learning deep feature embeddings via a triplet loss guided by the Neurogram Similarity Index Measure (NSIM) to capture degradation intensity. During inference, the similarity score between any two audio samples is computed through Euclidean distance of their embeddings. NOMAD is fully unsupervised and can be used in general perceptual audio tasks for audio analysis e.g.
- Categories:
31 Views
- Read more about ASSESSING VIBROACOUSTIC SOUND MASSAGE THROUGH THE BIOSIGNAL OF HUMAN SPEECH: EVIDENCE OF IMPROVED WELLBEING
- Log in to post comments
Stress has notorious and debilitating effects on individuals and entire industries alike, with instances of stress continuing to rise post-pandemic. We investigate here (1) if the new technology of Vibroacoustic Sound Massage (VSM) has beneficial effects on user wellbeing and (2) if we can measure these effects based on the biosignal of speech prosody. Forty participants read a text before and after VSM treatment (45 min). The 80 readings were subjected to a multi-parameteric acoustic-prosodic analysis.
- Categories:
30 Views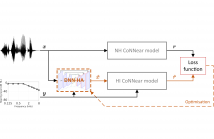
- Read more about DNN-HA: A DNN-based hearing-aid strategy for real-time processing
- Log in to post comments
Although hearing aids (HAs) can compensate for elevated hearing thresholds using sound amplification, they often fail to restore auditory perception in adverse listening conditions. Here, we present a deep-neural-network (DNN) HA processing strategy that can provide individualised sound processing for the audiogram of a listener using a single model architecture. Our multi-purpose HA model can be used for different individuals and can process audio inputs of 3.2 ms in <0.5 ms, thus paving the way for precise DNN-based treatments of hearing loss that can be embedded in hearing devices.
- Categories:
59 Views
- Read more about THE EFFECT OF PARTIAL TIME-FREQUENCY MASKING OF THE DIRECT SOUND ON THE PERCEPTION OF REVERBERANT SPEECH
- Log in to post comments
The perception of sound in real-life acoustic environments, such as enclosed rooms or open spaces with reflective objects, is affected by reverberation. Hence, reverberation is extensively studied in the context of auditory perception, with many studies highlighting the importance of the direct sound for perception. Based on this insight, speech processing methods often use time-frequency (TF) analysis to detect TF bins that are dominated by the direct sound, and then use the detected bins to reproduce or enhance the speech signals.
- Categories:
12 Views
- Read more about MULTI-LINGUAL MULTI-TASK SPEECH EMOTION RECOGNITION USING WAV2VEC 2.0
- Log in to post comments
Speech Emotion Recognition (SER) has several use cases for
Digital Entertainment Content (DEC) in Over-the-top (OTT)
services, emotive Text-to-Speech (TTS) engines and voice
assistants. In this work, we present a Multi-Lingual (MLi) and
Multi-Task Learning (MTL) audio only SER system based on
the multi-lingual pre-trained wav2vec 2.0 model. The model
is fine-tuned on 25 open source datasets in 13 locales across
7 emotion categories. We show that, a) Our wav2vec 2.0
single task based model outperforms Pre-trained Audio Neural
- Categories:
47 Views
- Read more about Deep Learning for Prominence Detection in Children's Read Speech
- Log in to post comments
Poster.pdf
- Categories:
25 Views
- Read more about Internet Streaming Audio Based Speech Perception Threshold Measurement in Cochlear Implant Users
- Log in to post comments
Traditional face-to-face subjective listening test has become a challenge due to the COVID-19 pandemic. We developed a remote assessment system with Tencent Meeting, a video conferencing application, to address this issue. This paper
- Categories:
10 Views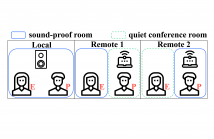
- Read more about Internet Streaming Audio Based Speech Perception Threshold Measurement in Cochlear Implant Users
- Log in to post comments
Traditional face-to-face subjective listening test has become a challenge due to the COVID-19 pandemic. We developed a remote assessment system with Tencent Meeting, a video conferencing application, to address this issue. This paper
- Categories:
16 Views
- Read more about A NOISE-ROBUST SIGNAL PROCESSING STRATEGY FOR COCHLEAR IMPLANTS USING NEURAL NETWORKS
- Log in to post comments
- Categories:
19 Views