
- Read more about Source Coding of Audio Signals with a Generative Model
- 2 comments
- Log in to post comments
We consider source coding of audio signals with the help of a generative model. We use a construction where a waveform is first quantized, yielding a finite bitrate representation. The waveform is then reconstructed by random sampling from a model conditioned on the quantized waveform. The proposed coding scheme is theoretically analyzed. Using SampleRNN as the generative model, we demonstrate that the proposed coding structure provides performance competitive with state-of-the-art source coding tools for specific categories of audio signals.
- Categories:
 139 Views
139 Views
- Read more about Regularized state estimation and parameter learning via augmented Lagrangian Kalman smoother method
- Log in to post comments
In this article, we address the problem of estimating the state and learning of the parameters in a linear dynamic system with generalized $L_1$-regularization. Assuming a sparsity prior on the state, the joint state estimation and parameter learning problem is cast as an unconstrained optimization problem. However, when the dimensionality of state or parameters is large, memory requirements and computation of learning algorithms are generally prohibitive.
- Categories:
76 Views
- Read more about Modeling nonlinear audio effects with end-to-end deep neural networks
- Log in to post comments
Audio processors whose parameters are modified periodically
over time are often referred as time-varying or modulation based
audio effects. Most existing methods for modeling these type of
effect units are often optimized to a very specific circuit and cannot
be efficiently generalized to other time-varying effects. Based on
convolutional and recurrent neural networks, we propose a deep
learning architecture for generic black-box modeling of audio processors
with long-term memory. We explore the capabilities of
- Categories:
55 Views
- Read more about ONLINE SINGING VOICE SEPARATION USING A RECURRENT ONE-DIMENSIONAL U-NET TRAINED WITH DEEP FEATURE LOSSES
- Log in to post comments
This paper proposes an online approach to the singing voice separation problem. Based on a combination of one-dimensional convolutional layers along the frequency axis and recurrent layers to enforce temporal coherency, state-of-the-art performance is achieved. The concept of using deep features in the loss function to guide training and improve the model’s performance is also investigated.
- Categories:
48 Views
- Read more about TRANSCRIBING LYRICS FROM COMMERCIAL SONG AUDIO: THE FIRST STEP TOWARDS SINGING CONTENT PROCESSING
- Log in to post comments
Spoken content processing (such as retrieval and browsing) is maturing, but the singing content is still almost completely left out. Songs are human voice carrying plenty of semantic information just as speech, and may be considered as a special type of speech with highly flexible prosody. The various problems in song audio, for example the significantly changing phone duration over highly flexible pitch contours, make the recognition of lyrics from song audio much more difficult. This paper reports an initial attempt towards this goal.
poster_v4.pdf
- Categories:
14 Views
- Read more about Limiting Numerical Precision of Neural Networks to Achieve Real-time Voice Activity Detection
- Log in to post comments
- Categories:
15 Views
- Read more about CONVOLUTIONAL SEQUENCE TO SEQUENCE MODEL WITH NON-SEQUENTIAL GREEDY DECODING FOR GRAPHEME TO PHONEME CONVERSION
- Log in to post comments
The greedy decoding method used in the conventional sequence-to-sequence models is prone to producing a model with a compounding
of errors, mainly because it makes inferences in a fixed order, regardless of whether or not the model’s previous guesses are correct.
We propose a non-sequential greedy decoding method that generalizes the greedy decoding schemes proposed in the past. The proposed
method determines not only which token to consider, but also which position in the output sequence to infer at each inference step.
- Categories:
380 Views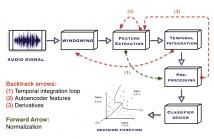
- Read more about Extended Pipeline for Content-Based Feature Engineering in Music Genre Recognition
- Log in to post comments
We present a feature engineering pipeline for the construction of musical signal characteristics, to be used for the design of a supervised model for musical genre identification. The key idea is to extend the traditional two-step process of extraction and classification with additive stand-alone phases which are no longer organized in a waterfall scheme. The whole system is realized by traversing backtrack arrows and cycles between various stages.
- Categories:
50 ViewsMetric learning for music is an important problem for many music information retrieval (MIR) applications such as music generation, analysis, retrieval, classification and recommendation. Traditional music metrics are mostly defined on linear transformations of handcrafted audio features, and may be improper in many situations given the large variety of mu- sic styles and instrumentations.
presentation.pdf
- Categories:
24 Views
- Read more about Song recommendation with Non-Negative Matrix factorization and graph total variation
- Log in to post comments
This work formulates song recommendation as a matrix completion problem that benefits from collaborative filter- ing through Non-negative Matrix Factorization (NMF) and content-based filtering via total variation (TV) on graphs. The graphs encode both playlist proximity information and song similarity, using a rich combination of audio, meta-data and social features. As we demonstrate, our hybrid recom- mendation system is very versatile and incorporates several well-known methods while outperforming them. Particularly, we show on real-world data that our model overcomes w.r.t.
- Categories:
24 Views