
- Read more about One-class Learning Towards Synthetic Voice Spoofing Detection (Poster)
- Log in to post comments
Human voices can be used to authenticate the identity of the speaker, but the automatic speaker verification (ASV) systems are vulnerable to voice spoofing attacks, such as impersonation, replay, text-to-speech, and voice conversion. Recently, researchers developed anti-spoofing techniques to improve the reliability of ASV systems against spoofing attacks. However, most methods encounter difficulties in detecting unknown attacks in practical use, which often have different statistical distributions from known attacks.
- Categories:
 47 Views
47 Views
- Read more about Infant Crying Detection in Real-World Environments
- Log in to post comments
Most existing cry detection models have been tested with data collected in controlled settings. Thus, the extent to which they generalize to noisy and lived environments is unclear. In this paper, we evaluate several established machine learning approaches including a model leveraging both deep spectrum and acoustic features. This model was able to recognize crying events with F1 score 0.613 (Precision: 0.672, Recall: 0.552), showing improved external validity over existing methods at cry detection in everyday real-world settings.
- Categories:
17 Views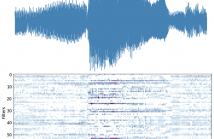
- Read more about Deep Convolutional and Recurrent Networks for Polyphonic Instrument Classification from Monophonic Raw Audio Waveforms
- Log in to post comments
Sound Event Detection and Audio Classification tasks are traditionally addressed through time-frequency representations of audio signals such as spectrograms. However, the emergence of deep neural networks as efficient feature extractors has enabled the direct use of audio signals for classification purposes. In this paper, we attempt to recognize musical instruments in polyphonic audio by only feeding their raw waveforms into deep learning models.
- Categories:
33 Views
The recognition of music genre and the discrimination between music and speech are important components of modern digital music systems. Depending on the acquisition conditions, such as background environment, these signals may come from different probability distributions, making the learning problem complicated. In this context, domain adaptation is a key theory to improve performance. Considering data coming from various background conditions, the adaptation scenario is called multi-source.
- Categories:
12 Views
- Read more about Leveraging the structure of musical preference in content-aware music recommendation
- Log in to post comments
State-of-the-art music recommendation systems are based on collaborative filtering, which predicts a user's interest from his listening habits and similarities with other users' profiles. These approaches are agnostic to the song content, and therefore face the cold-start problem: they cannot recommend novel songs without listening history. To tackle this issue, content-aware recommendation incorporates information about the songs that can be used for recommending new items.
- Categories:
7 Views
- Read more about UNSUPERVISED MUSICAL TIMBRE TRANSFER FOR NOTIFICATION SOUNDS
- Log in to post comments
We present a method to transform artificial notification sounds into various musical timbres. To tackle the issues of ambiguous timbre definition, the lack of paired notification-music sample sets, and the lack of sufficient training data of notifications, we adapt the problem for a cycle-consistent generative adversarial network and train it with unpaired samples from the source and the target domains. In addition, instead of training the network with notification sound samples, we train it with video game music samples that share similar timbral features.
- Categories:
24 Views
- Read more about Audio-based Detection of Explicit Content in Music
- Log in to post comments
We present a novel automatic system for performing explicit content detection directly on the audio signal. Our modular approach uses an audio-to-character recognition model, a keyword spotting model associated with a dictionary of carefully chosen keywords, and a Random Forest classification model for the final decision. To the best of our knowledge, this is the first explicit content detection system based on audio only. We demonstrate the individual relevance of our modules on a set of sub-tasks and compare our approach to a lyrics-informed oracle and an end-to-end naive architecture.
- Categories:
81 Views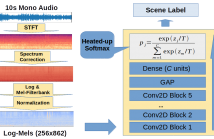
- Read more about Acoustic Scene Classification for Mismatched Recording Devices Using Heated-Up Softmax and Spectrum Correction
- Log in to post comments
Deep neural networks (DNNs) are successful in applications with matching inference and training distributions. In realworld scenarios, DNNs have to cope with truly new data samples during inference, potentially coming from a shifted data distribution. This usually causes a drop in performance. Acoustic scene classification (ASC) with different recording devices is one of this situation. Furthermore, an imbalance in quality and amount of data recorded by different devices causes severe challenges. In this paper, we introduce two calibration methods to tackle these challenges.
- Categories:
23 Views
- Read more about RAW WAVEFORM BASED END-TO-END DEEP CONVOLUTIONAL NETWORK FOR SPATIAL LOCALIZATION OF MULTIPLE ACOUSTIC SOURCES
- Log in to post comments
In this paper, we present an end-to-end deep convolutional neural network operating on multi-channel raw audio data to localize multiple simultaneously active acoustic sources in space. Previously reported end-to-end deep learning based approaches work well in localizing a single source directly from multi-channel raw-audio, but are not easily extendable to localize multiple sources due to the well known permutation problem.
- Categories:
44 Views
- Read more about VaPar Synth - A Variational Parametric Model for Audio Synthesis
- 1 comment
- Log in to post comments
With the advent of data-driven statistical modeling and abundant computing power, researchers are turning increasingly to deep learning for audio synthesis. These methods try to model audio signals directly in the time or frequency domain. In the interest of more flexible control over the generated sound, it could be more useful to work with a parametric representation of the signal which corresponds more directly to the musical attributes such as pitch, dynamics and timbre.
- Categories:
60 Views