
- Read more about FRAUG: A FRAME RATE BASED DATA AUGMENTATION METHOD FOR DEPRESSION DETECTION FROM SPEECH SIGNALS
- Log in to post comments
- Categories:
 64 Views
64 Views
- Read more about Constant Q Cepstral Coefficients for Normal vs. Pathological Infant Cry
- Log in to post comments
- Categories:
30 Views
- Read more about Multimodal Depression Classification Using Articulatory Coordination Features and Hierarchical Attention Based Text Embeddings
- Log in to post comments
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to unimodal classifiers (7.5% and 13.7% for audio and text respectively).
3649_poster.pdf
- Categories:
34 Views
- Read more about SERAB: A MULTI-LINGUAL BENCHMARK FOR SPEECH EMOTION RECOGNITION
- Log in to post comments
The Speech Emotion Recognition Adaptation Benchmark (SERAB) is a new framework to evaluate the performance and generalization capacity of different approaches for utterance-level SER. The benchmark is composed of nine datasets for SER in six languages. We used the proposed framework to evaluate a selection of standard hand-crafted feature sets and state-of-the-art DNN representations. The results highlight that using only a subset of the data included in SERAB can result in biased evaluation, while compliance with the proposed protocol can circumvent this issue.
- Categories:
19 Views
- Read more about Automatic Assessment of the Degree of Clinical Depression from Speech Using X-Vectors
- Log in to post comments
Depression is a frequent and curable psychiatric disorder, detrimentally affecting daily activities, harming both work-place productivity and personal relationships. Among many other symptoms, depression is associated with disordered
speech production, which might permit its automatic screening by means of the speech of the subject. However, the choice of actual features extracted from the recordings is not trivial. In this study, we employ x-vectors, a DNN-based
- Categories:
26 Views
- Read more about AN ATTENTION MODEL FOR HYPERNASALITY PREDICTION IN CHILDREN WITH CLEFT PALATE
- Log in to post comments
Hypernasality refers to the perception of abnormal nasal resonances in vowels and voiced consonants. Estimation of hypernasality severity from connected speech samples involves learning a mapping between the frame-level features and utterance-level clinical ratings of hypernasality. However, not all speech frames contribute equally to the perception of hypernasality.
- Categories:
19 Views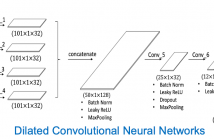
- Read more about Exploiting Vocal Tract Coordination Using Dilated CNNs for Depression Detection in Naturalistic Environments
- Log in to post comments
Depression detection from speech continues to attract significant research attention but remains a major challenge, particularly when the speech is acquired from diverse smartphones in natural environments. Analysis methods based on vocal tract coordination have shown great promise in depression and cognitive impairment detection for quantifying relationships between features over time through eigenvalues of multi-scale cross-correlations.
- Categories:
63 Views
- Read more about VOICE BASED CLASSIFICATION OF PATIENTS WITH AMYOTROPHIC LATERAL SCLEROSIS, PARKINSON'S DISEASE AND HEALTHY CONTROLS WITH CNN-LSTM USING TRANSFER LEARNING
- Log in to post comments
In this paper, we consider 2-class and 3-class classification problems for classifying patients with Amyotropic Lateral Sclerosis (ALS), Parkinson’s Disease (PD) and Healthy Controls (HC) using a CNN-LSTM network. Classification performance is examined for three different tasks, namely, Spontaneous speech (SPON), Diadochoki-netic rate (DIDK) and Sustained Phonation (PHON). Experiments are conducted using speech data recorded from 60 ALS, 60 PD and60 HC subjects. Classification using SVM and DNN are considered baseline schemes.
- Categories:
83 Views- Read more about Ensemble feature selection for domain adaptation in speech emotion recognition
- Log in to post comments
When emotion recognition systems are used in new domains, the classification performance usually drops due to mismatches between training and testing conditions. Annotations of new data in the new domain is expensive and time demanding. Therefore, it is important to design strategies that efficiently use limited amount of new data to improve the robustness of the classification system. The use of ensembles is an attractive solution, since they can be built to perform well across different mismatches. The key challenge is to create ensembles that are diverse.
- Categories:
17 Views- Read more about Incremental adaptation using active learning for acoustic emotion recognition
- Log in to post comments
The performance of speech emotion classifiers greatly degrade when the training conditions do not match the testing conditions. This problem is observed in cross-corpora evaluations, even when the corpora are similar. The lack of generalization is particularly problematic when the emotion classifiers are used in real applications. This study addresses this problem by combining active learning (AL) and supervised domain adaptation (DA) using an elegant approach for support vector machine (SVM).
Poster-CB.pdf
- Categories:
20 Views