
- Read more about ICASSP 2019 Poster - Privacy-preserving Paralinguistic Tasks
- Log in to post comments
Speech is one of the primary means of communication for humans. It can be viewed as a carrier for information on several levels as it conveys not only the meaning and intention predetermined by a speaker, but also paralinguistic and extralinguistic information about the speaker’s age, gender, personality, emotional state, health state and affect. This makes it a particularly sensitive biometric, that should be protected.
- Categories:
 38 Views
38 Views
- Read more about Privacy-preserving Paralinguistic Tasks
- Log in to post comments
Speech is one of the primary means of communication for humans. It can be viewed as a carrier for information on several levels as it conveys not only the meaning and intention predetermined by a speaker, but also paralinguistic and extralinguistic information about the speaker’s age, gender, personality, emotional state, health state and affect. This makes it a particularly sensitive biometric, that should be protected.
- Categories:
31 Views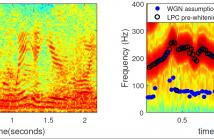
- Read more about A Study on how Pre-Whitening Influences Fundamental Frequency Estimation
- Log in to post comments
This paper deals with the influence of pre-whitening for the task of fundamental frequency estimation in noisy conditions. Parametric fundamental frequency estimators commonly assume that the noise is white and Gaussian and, therefore, they are only statistically efficient under those conditions. The noise is coloured in many practical applications and this will often result in problems of misidentifying an integer divisor or multiple of the true fundamental frequency (i.e., octave errors).
- Categories:
105 Views
- Read more about AN INTERACTION-AWARE ATTENTION NETWORK FOR SPEECH EMOTION RECOGNITION IN SPOKEN DIALOGS
- Log in to post comments
Obtaining robust speech emotion recognition (SER) in scenarios of spoken interactions is critical to the developments of next generation human-machine interface. Previous research has largely focused on performing SER by modeling each utterance of the dialog in isolation without considering the transactional and dependent nature of the human-human conversation. In this work, we propose an interaction-aware attention network (IAAN) that incorporate contextual information in the learned vocal representation through a novel attention mechanism.
- Categories:
45 Views
- Read more about Improving Speech Emotion Recognition with Unsupervised Representation Learning on Unlabeled Speech
- Log in to post comments
- Categories:
67 Views
- Read more about A DEEP NEURAL NETWORK BASED END TO END MODEL FOR JOINT HEIGHT AND AGE ESTIMATION FROM SHORT DURATION SPEECH
- Log in to post comments
Automatic height and age prediction of a speaker has a wide variety of applications in speaker profiling, forensics etc. Often in such applications only a few seconds of speech data is available to reliably estimate the speaker parameters. Traditionally, age and height were predicted separately using different estimation algorithms. In this work, we propose a unified DNN architecture to predict both height and age of a speaker for short durations of speech.
- Categories:
57 Views
- Read more about PERCEPTUALLY ENHANCED SINGLE FREQUENCY FILTERING FOR DYSARTHRIC SPEECH DETECTION AND INTELLIGIBILITY ASSESSMENT
- Log in to post comments
This paper proposes a new speech feature representation that improves the intelligibility assessment of dysarthric speech. The formulation of the feature set is motivated from the human auditory perception and high time-frequency resolution property of single frequency filtering (SFF) technique. The proposed features are named as perceptually enhanced single frequency cepstral coefficients (PESFCC). As a part of SFF technique implementation, speech signal passed through a single pole complex bandpass filter bank to obtain high-resolution time-frequency distribution.
- Categories:
68 Views
- Read more about JOINT BAYESIAN ESTIMATION OF TIME-VARYING LP PARAMETERS AND EXCITATION FOR SPEECH
- Log in to post comments
We consider the joint estimation of time-varying linear prediction (TVLP) filter coefficients and the excitation signal parameters for the analysis of long-term speech segments. Traditional approaches to TVLP estimation assume linear expansion of the coefficients in a set of known basis functions only. But, excitation signal is also time-varying, which affects the estimation of TVLP filter parameters. In this paper, we propose a Bayesian approach, to incorporate the nature of excitation signal and also adapt regularization of the filter parameters.
poster.pdf
- Categories:
33 Views
- Read more about A DEEPER LOOK AT GAUSSIAN MIXTURE MODEL BASED ANTI-SPOOFING SYSTEMS
- Log in to post comments
- Categories:
37 Views
- Read more about AN OPEN-SOURCE SPEAKER GENDER DETECTION FRAMEWORK FOR MONITORING GENDER EQUALITY
- Log in to post comments
This paper presents an approach based on acoustic analysis to describe gender equality in French audiovisual streams, through the estimation of male and female speaking time. Gender detection systems based on Gaussian Mixture Models, i-vectors and Convolutional Neural Networks (CNN) were trained using an internal database of 2,284 French speakers and evaluated using REPERE challenge corpus. The CNN system obtained the best performance with a frame-level gender detection F-measure of 96.52 and a hourly women speaking time percentage error bellow 0.6%.
icasspPoster.pdf
- Categories:
69 Views