
- Read more about Soft-Target Training with Ambiguous Emotional Utterances for DNN-based Speech Emotion Classification
- Log in to post comments
- Categories:
 59 Views
59 Views
- Read more about UNSUPERVISED CROSS-CORPUS SPEECH EMOTION RECOGNITION USING DOMAIN-ADAPTIVE SUBSPACE LEARNING
- Log in to post comments
In this paper, we investigate an interesting problem, i.e., unsupervised cross-corpus speech emotion recognition (SER), in which the training and testing speech signals come from two different speech emotion corpora. Meanwhile, the training speech signals are labeled, while the label information of the testing speech signals is entirely unknown. Due to this setting, the training (source) and testing (target) speech signals may have different feature distributions and therefore lots of existing SER methods would not work.
- Categories:
15 Views
- Read more about UNSUPERVISED CROSS-CORPUS SPEECH EMOTION RECOGNITION USING DOMAIN-ADAPTIVE SUBSPACE LEARNING
- Log in to post comments
- Categories:
33 Views
- Read more about UNOBTRUSIVE MONITORING OF SPEECH IMPAIRMENTS OF PARKINSON'S DISEASE PATIENTS THROUGH MOBILE DEVICES
- Log in to post comments
Parkinson’s disease (PD) produces several speech impairments in the patients. Automatic classification of PD patients is performed considering speech recordings collected in non- controlled acoustic conditions during normal phone calls in a unobtrusive way. A speech enhancement algorithm is applied to improve the quality of the signals. Two different classification approaches are considered: the classification of PD patients and healthy speakers and a multi-class experiment to classify patients in several stages of the disease.
icassp.pdf
- Categories:
28 Views
- Read more about Prediction of Negative Symptoms of Schizophrenia from Emotion Related Low-Level Speech Signals
- Log in to post comments
Negative symptoms of schizophrenia are often associated with the blunting of emotional affect which creates a serious impediment in the daily functioning of the patients. Affective prosody is almost always adversely impacted in such cases, and is known to exhibit itself through the low-level acoustic signals of prosody. To automate and simplify the process of assessment of severity of emotion related symptoms of schizophrenia, we utilized these low-level acoustic signals to predict the expert subjective ratings assigned by a trained psychologist during an interview with the patient.
- Categories:
21 Views
- Read more about MEASURING UNCERTAINTY IN DEEP REGRESSION MODELS: THE CASE OF AGE ESTIMATION FROM SPEECH
- Log in to post comments
icassp.pptx
icassp.pptx
- Categories:
25 Views- Read more about Learning Cross-lingual Knowledge with Multilingual BLSTM for Emphasis Detection with Limited Training Data
- Log in to post comments
Bidirectional long short-term memory (BLSTM) recurrent neural network (RNN) has achieved state-of-the-art performance in many sequence processing problems given its capability in capturing contextual information. However, for languages with limited amount of training data, it is still difficult to obtain a high quality BLSTM model for emphasis detection, the aim of which is to recognize the emphasized speech segments from natural speech.
- Categories:
7 Views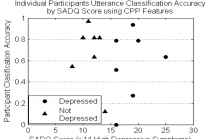
- Read more about DETECTING STRESS AND DEPRESSION IN ADULTS WITH APHASIA THROUGH SPEECH ANALYSIS
- Log in to post comments
Aphasia is an acquired communication disorder resulting from brain damage and impairs an individual’s ability to use, produce, and comprehend language. Loss of communication skills can be stressful and may result in depression, yet most stress and depression diagnostic tools are designed for adults without aphasia. This project is a research effort to predict stress and depression from acoustic profiles of adults with aphasia using linear support-vector regression. The labels were obtained through caregiver surveys (SADQ-10) or surveys not designed for adults with aphasia (PSS).
- Categories:
22 Views- Read more about AUTOMATIC DETECTION OF SYLLABLE STRESS USING SONORITY BASED PROMINENCE FEATURES FOR PRONUNCIATION EVALUATION
- Log in to post comments
Automatic syllable stress detection is useful in assessing and diagnosing the quality of the pronunciation of second language (L2) learners in an automated way. Typically, the syllable stress depends on three prominence measures -- intensity level, duration, pitch -- around the sound unit with the highest sonority in the respective syllable. Stress detection is often formulated as a binary classification task using cues from the feature contours representing the prominence measures.
ICASSP17.pdf
- Categories:
13 Views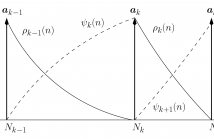
- Read more about NON-NEGATIVE TEMPORAL DECOMPOSITION REGULARIZATION WITH AN AUGMENTED LAGRANGIAN
- Log in to post comments
Nonnegative matrix factorization (NMF) has recently been applied to temporal decomposition (TD) of speech spectral envelopes represented by line spectral frequencies. A couple of inherent TD constraints, which are otherwise handled as ad hoc exceptions, has also been incorporated using NMF, including LSF ordering and monotonic event functions. Here, these constraints are analyzed and a third inherent constraint is incorporated into an NMF analysis.
- Categories:
20 Views