- Read more about Study of dense network approaches for speech emotion recognition
- Log in to post comments
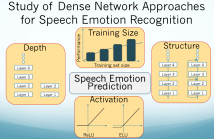
Deep neural networks have been proven to be very effective in various classification problems and show great promise for emotion recognition from speech. Studies have proposed various architectures that further improve the performance of emotion recognition systems. However, there are still various open questions regarding the best approach to building a speech emotion recognition system. Would the system’s performance improve if we have more labeled data? How much do we benefit from data augmentation? What activation and regularization schemes are more beneficial?
- Categories:
 21 Views
21 Views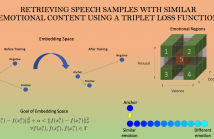
- Read more about Retrieving speech samples with similar emotional content using a triplet loss function
- Log in to post comments
The ability to identify speech with similar emotional content is valuable to many applications, including speech retrieval, surveil- lance, and emotional speech synthesis. While current formulations in speech emotion recognition based on classification or regression are not appropriate for this task, solutions based on preference learn- ing offer appealing approaches for this task. This paper aims to find speech samples that are emotionally similar to an anchor speech sample provided as a query. This novel formulation opens interest- ing research questions.
- Categories:
60 Views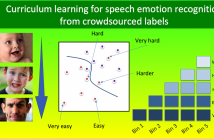
- Read more about Curriculum learning for speech emotion recognition from crowdsourced labels
- Log in to post comments
This study introduces a method to design a curriculum for machine-learning to maximize the efficiency during the training process of deep neural networks (DNNs) for speech emotion recognition. Previous studies in other machine-learning problems have shown the benefits of training a classifier following a curriculum where samples are gradually presented in increasing level of difficulty. For speech emotion recognition, the challenge is to establish a natural order of difficulty in the training set to create the curriculum.
- Categories:
66 Views
- Read more about Modeling uncertainty in predicting emotional attributes from spontaneous speech
- Log in to post comments
- Categories:
33 Views
- Read more about ANALYSIS OF ACOUSTIC FEATURES FOR SPEECH SOUND BASED CLASSIFICATION OF ASTHMATIC AND HEALTHY SUBJECTS
- Log in to post comments
Non-speech sounds (cough, wheeze) are typically known to perform better than speech sounds for asthmatic and healthy subject
classification. In this work, we use sustained phonations of speech sounds, namely, /A:/, /i:/, /u:/, /eI/, /oU/, /s/, and /z/ from 47 asthmatic and 48 healthy controls. We consider INTERSPEECH 2013 Computational Paralinguistics Challenge baseline (ISCB)
- Categories:
41 Views
- Read more about A Comparison of Boosted Deep Neural Networks for Voice Activity Detection
- Log in to post comments
Voice activity detection (VAD) is an integral part of speech processing for real world problems, and a lot of work has been done to improve VAD performance. Of late, deep neural networks have been used to detect the presence of speech and this has offered tremendous gains. Unfortunately, these efforts have been either restricted to feed-forward neural networks that do not adequately capture frequency and temporal correlations, or the recurrent architectures have not been adequately tested in noisy environments.
williamson.pdf
- Categories:
106 Views
- Read more about Similarity Metric Based on Siamese Neural Networks for Voice Casting
- Log in to post comments
- Categories:
43 Views
- Read more about Dimensional Analysis of Laughter in Female Conversational Speech
- Log in to post comments
How do people hear laughter in expressive, unprompted speech? What is the range of expressivity and function of laughter in this speech, and how can laughter inform the recognition of higher-level expressive dimensions in a corpus? This paper presents a scalable method for collecting natural human description of laughter, transforming the description to a vector of quantifiable laughter dimensions, and deriving baseline classifiers for the different dimensions of expressive laughter.
- Categories:
6 Views
Obstructive sleep apnea (OSA) is a prevalent sleep disorder, responsible for a decrease of people’s quality of life, and significant morbidity and mortality associated with hypertension and cardiovascular diseases. OSA is caused by anatomical and functional alterations in the upper airways, thus we hypothesize that the speech properties of OSA patients are altered, making it possible to detect OSA through voice analysis.
- Categories:
27 Views
- Read more about Learning Voice Source Related Information for Depression Detection
- Log in to post comments
- Categories:
28 Views