
- Read more about Exploiting Language-Mismatched Phoneme Recognizers for Unsupervised Acoustic Modeling
- Log in to post comments
This paper describes an investigation on acoustic modeling in the absence of transcribed training data. We propose to use language-mismatched phoneme recognizers to assist unsupervised segmentation and segment clustering of a new language. Using a language-mismatched recognizer, an input utterance is divided into many variable-length segments. Each segment is represented by a feature vector that is derived from the phoneme posterior probabilities.
slides.pdf
- Categories:
 23 Views
23 Views- Read more about EXPLOITING LSTM STRUCTURE IN DEEP NEURAL NETWORKS FOR SPEECH RECOGNITION
- Log in to post comments
- Categories:
12 Views- Read more about Compact Kernel Models for Acoustic Modeling via Random Feature Selection
- Log in to post comments
A simple but effective method is proposed for learning compact random feature models that approximate non-linear kernel methods, in the context of acoustic modeling. The method is able to explore a large number of non-linear features while maintaining a compact model via feature selection more efficiently than existing approaches. For certain kernels, this random feature selection may be regarded as a means of non-linear feature selection at the level of the raw input features, which motivates additional methods for computational improvements.
- Categories:
10 Views- Read more about On Training the Recurrent Neural Network Encoder-Decoder for Large Vocabulary End-to-end Speech Recognition
- Log in to post comments
Recently, there has been an increasing interest in end-to-end speech
recognition using neural networks, with no reliance on hidden
Markov models (HMMs) for sequence modelling as in the standard
hybrid framework. The recurrent neural network (RNN) encoder-decoder
is such a model, performing sequence to sequence mapping
without any predefined alignment. This model first transforms the
input sequence into a fixed length vector representation, from which
the decoder recovers the output sequence. In this paper, we extend
- Categories:
20 Views- Read more about Deep convolutional acoustic word embeddings using word-pair side information
- Log in to post comments
Recent studies have been revisiting whole words as the basic modelling unit in speech recognition and query applications, instead of phonetic units. Such whole-word segmental systems rely on a function that maps a variable-length speech segment to a vector in a fixed-dimensional space; the resulting acoustic word embeddings need to allow for accurate discrimination between different word types, directly in the embedding space. We compare several old and new approaches in a word discrimination task.
- Categories:
6 Views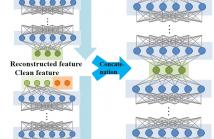
- Read more about Two-Stage Noise Aware Training Using Asymmetric Deep Denoising Autoencoder
- Log in to post comments
Ever since the deep neural network (DNN)-based acoustic model appeared, the recognition performance of automatic peech recognition has been greatly improved. Due to this achievement, various researches on DNN-based technique for noise robustness are also in progress. Among these approaches, the noise-aware training (NAT) technique which aims to improve the inherent robustness of DNN using noise estimates has shown remarkable performance. However, despite the great performance, we cannot be certain whether NAT is an optimal method for sufficiently utilizing the inherent robustness of DNN.
- Categories:
31 Views