
- Read more about On Modular Training of Neural Acoustics-to-Word Model for LVCSR
- Log in to post comments
End-to-end (E2E) automatic speech recognition (ASR) systems directly map acoustics to words using a unified model. Previous works
mostly focus on E2E training a single model which integrates acoustic and language model into a whole. Although E2E training benefits
from sequence modeling and simplified decoding pipelines, large
amount of transcribed acoustic data is usually required, and traditional acoustic and language modelling techniques cannot be utilized. In this paper, a novel modular training framework of E2E ASR
- Categories:
 7 Views
7 Views
Vanishing long-term gradients are a major issue in training standard recurrent neural networks (RNNs), which can be alleviated by long short-term memory (LSTM) models with memory cells. However, the extra parameters associated with the memory cells mean an LSTM layer has four times as many parameters as an RNN with the same hidden vector size. This paper addresses the vanishing gradient problem using a high order RNN (HORNN) which has additional connections from multiple previous time steps.
- Categories:
16 Views- Read more about Joint CTC-Attention based End-to-End Speech Recognition using Multi-Task Learning
- Log in to post comments
Recently, there has been an increasing interest in end-to-end speech recognition that directly transcribes speech to text without any predefined alignments. One approach is the attention-based encoder decoder framework that learns a mapping between variable-length input and output sequences in one step using a purely data-driven method.
- Categories:
51 Views- Read more about LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER ! DNN ACOUSTIC MODELS
- Log in to post comments
Conventional deep neural networks (DNN) for speech acoustic modeling rely on Gaussian mixture models (GMM) and hidden Markov model (HMM) to obtain binary class labels as the targets for DNN training. Subword classes in speech recognition systems correspond to context-dependent tied states or senones. The present work addresses some limitations of GMM-HMM senone alignments for DNN training. We hypothesize that the senone probabilities obtained from a DNN trained with binary labels can provide more accurate targets to learn better acoustic models.
- Categories:
8 Views- Read more about ICASSP2017 Poster (Paper #4319)
- Log in to post comments
The performance of automatic speech recognition (ASR) system is often degraded in adverse real-world environments. In recent times, deep learning has successfully emerged as a breakthrough for acoustic modeling in ASR; accordingly, deep-neural-network(DNN)-based speech feature enhancement (FE) approaches have attracted much attention owing to their powerful modeling capabilities. However, DNN-based approaches are unable to achieve remarkable performance improvements for speech with severe distortion in the test environments different from training environments.
- Categories:
20 Views- Read more about Joint Optimisation of Tandem Systems using Gaussian Mixture Density Neural Network Discriminative Sequence Training
- Log in to post comments
- Categories:
14 Views- Read more about PERSONALIZED ACOUSTIC MODELING BY WEAKLY SUPERVISED MULTI-TASK DEEP LEARNING USING ACOUSTIC TOKENS DISCOVERED FROM UNLABELED DATA
- Log in to post comments
It is well known that recognizers personalized to each user are much more effective than user-independent recognizers. With the popularity of smartphones today, although it is not difficult to collect a large set of audio data for each user, it is difficult to transcribe it. However, it is now possible to automatically discover acoustic tokens from unlabeled personal data in an unsupervised way.
- Categories:
4 Views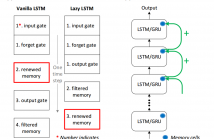
- Read more about MEMORY VISUALIZATION FOR GATED RECURRENT NEURAL NETWORKS IN SPEECH RECOGNITION
- Log in to post comments
Recurrent neural networks (RNNs) have shown clear superiority in sequence modeling, particularly the ones with gated units, such as long short-term memory (LSTM) and gated recurrent unit (GRU). However, the dynamic properties behind the remarkable performance remain unclear in many applications, e.g., automatic speech recognition (ASR). This paper employs visualization techniques to study the behavior of LSTM and GRU when performing speech recognition tasks.
- Categories:
12 Views- Read more about Exploring Tonal Information for Lhasa Dialect Acoustic Modeling
- Log in to post comments
Detailed analysis of tonal features for Tibetan Lhasa dialect is an important task for Tibetan automatic speech recognition (ASR) applications. However, it is difficult to utilize tonal information because it remains controversial how many tonal patterns the Lhasa dialect has. Therefore, few studies have focused on modeling the tonal information of the Lhasa dialect for speech recognition purpose. For this reason, we investigated influences of the tonal information on the performance of Lhasa Tibetan speech recognition.
- Categories:
15 Views