
- Read more about Speaker-aware Training of Attention-based End-to-End Speech Recognition using Neural Speaker Embeddings
- Log in to post comments
In speaker-aware training, a speaker embedding is appended to DNN input features. This allows the DNN to effectively learn representations, which are robust to speaker variability.
We apply speaker-aware training to attention-based end- to-end speech recognition. We show that it can improve over a purely end-to-end baseline. We also propose speaker-aware training as a viable method to leverage untranscribed, speaker annotated data.
- Categories:
 58 Views
58 Views
- Read more about Small energy masking for improved neural network training for end-to-end speech recognition
- Log in to post comments
In this paper, we present a Small Energy Masking (SEM) algorithm, which masks inputs having values below a certain threshold. More specifically, a time-frequency bin is masked if the filterbank energy in this bin is less than a certain energy threshold. A uniform distribution is employed to randomly generate the ratio of this energy threshold to the peak filterbank energy of each utterance in decibels. The unmasked feature elements are scaled so that the total sum of the feature values remain the same through this masking procedure.
- Categories:
37 Views
- Read more about Unsupervised Pre-training of Bidirectional Speech Encoders via Masked Reconstruction
- 2 comments
- Log in to post comments
- Categories:
65 Views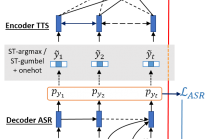
- Read more about END-TO-END FEEDBACK LOSS IN SPEECH CHAIN FRAMEWORK VIA STRAIGHT-THROUGH ESTIMATOR
- Log in to post comments
The speech chain mechanism integrates automatic speech recognition (ASR) and text-to-speech synthesis (TTS) modules into a single cycle during training. In our previous work, we applied a speech chain mechanism as a semi-supervised learning. It provides the ability for ASR and TTS to assist each other when they receive unpaired data and let them infer the missing pair and optimize the model with reconstruction loss.
- Categories:
73 Views
- Read more about PROMISING ACCURATE PREFIX BOOSTING FOR SEQUENCE-TO-SEQUENCE ASR
- Log in to post comments
- Categories:
15 Views
- Read more about PROMISING ACCURATE PREFIX BOOSTING FOR SEQUENCE-TO-SEQUENCE ASR
- Log in to post comments
- Categories:
10 Views
- Read more about Adversarial Speaker Adaptation
- Log in to post comments
We propose a novel adversarial speaker adaptation (ASA) scheme, in which adversarial learning is applied to regularize the distribution of deep hidden features in a speaker-dependent (SD) deep neural network (DNN) acoustic model to be close to that of a fixed speaker-independent (SI) DNN acoustic model during adaptation. An additional discriminator network is introduced to distinguish the deep features generated by the SD model from those produced by the SI model.
- Categories:
23 Views
- Read more about Conditional Teacher-Student Learning
- Log in to post comments
The teacher-student (T/S) learning has been shown to be effective for a variety of problems such as domain adaptation and model compression. One shortcoming of the T/S learning is that a teacher model, not always perfect, sporadically produces wrong guidance in form of posterior probabilities that misleads the student model towards a suboptimal performance.
- Categories:
56 Views
- Read more about PROMISING ACCURATE PREFIX BOOSTING FOR SEQUENCE-TO-SEQUENCE ASR
- Log in to post comments
- Categories:
10 Views
- Read more about MULTI-GEOMETRY SPATIAL ACOUSTIC MODELING FOR DISTANT SPEECH RECOGNITION
- Log in to post comments
The use of spatial information with multiple microphones can improve far-field automatic speech recognition (ASR) accuracy. However, conventional microphone array techniques degrade speech enhancement performance when there is an array geometry mismatch between design and test conditions. Moreover, such speech enhancement techniques do not always yield ASR accuracy improvement due to the difference between speech enhancement and ASR optimization objectives.
- Categories:
19 Views