
- Read more about Visualization of SLAM Backend Accelerator
- Log in to post comments
This research aims to develop energy-efficient hardware accelerators for Simultaneous Location And Mapping (SLAM) back end applications by employing algorithm-hardware co-design. Utilizing the iSAM2 algorithm, which uses graphical modeling to solve iterative Gauss-Newton problems, we continuously update maps by incorporating solutions from previous iterations or timesteps. We address the performance bottleneck arising from memory writes of intermediate results by modifying the original algorithm. Additionally, we analyze the algorithm's parallelizability to meet latency demands.
Poster.pdf
- Categories:
 43 Views
43 Views
- Read more about PositNN: Training Deep Neural Networks with Mixed Low-Precision Posit
- Log in to post comments
Low-precision formats have proven to be an efficient way to reduce not only the memory footprint but also the hardware resources and power consumption of deep learning computations. Under this premise, the posit numerical format appears to be a highly viable substitute for the IEEE floating-point, but its application to neural networks training still requires further research. Some preliminary results have shown that 8-bit (and even smaller) posits may be used for inference and 16-bit for training, while maintaining the model accuracy.
poster.pdf
- Categories:
11 Views
- Read more about dMazeRunner: Optimizing Convolutions on Dataflow Accelerators
- Log in to post comments
- Categories:
41 Views
- Read more about dMazeRunner: Optimizing Convolutions on Dataflow Accelerators
- Log in to post comments
- Categories:
22 Views
- Read more about dMazeRunner: Optimizing Convolutions on Dataflow Accelerators
- Log in to post comments
- Categories:
32 Views
- Read more about Back-to-Back Butterfly Network, an Adaptive Permutation Network for New Communication Standards
- Log in to post comments
- Categories:
11 Views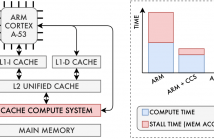
- Read more about PROCESSING CONVOLUTIONAL NEURAL NETWORKS ON CACHE
- Log in to post comments
With the advent of Big Data application domains, several Machine Learning (ML) signal-processing algorithms such as Convolutional Neural Networks (CNNs) are required to process progressively larger datasets at a great cost in terms of both compute power and memory bandwidth. Although dedicated accelerators have been developed targeting this issue, they usually require moving massive amounts of data across the memory hierarchy to the processing cores and low-level knowledge of how data is stored in the memory devices to enable in-/near-memory processing solutions.
- Categories:
25 Views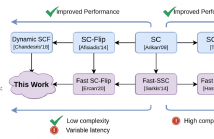
- Read more about SIMPLIFIED DYNAMIC SC-FLIP POLAR DECODING
- Log in to post comments
SC-Flip (SCF) decoding is a low-complexity polar code decoding algorithm alternative to SC-List (SCL) algorithm with small list sizes. To achieve the performance of the SCL algorithm with large list sizes, the Dynamic SC-Flip (DSCF) algorithm was proposed. However, DSCF involves logarithmic and exponential computations that are not suitable for practical hardware implementations. In this work, we propose a simple approximation that replaces the transcendental computations of DSCF decoding. Moreover, we show how to incorporate fast decoding techniques with the DSCF algorithm.
- Categories:
63 Views
- Read more about Lowering Dynamic Power of a Stream-based CNN Hardware Accelerator
- Log in to post comments
Custom hardware accelerators of Convolutional Neural Networks (CNN) provide a promising solution to meet real-time constraints for a wide range of applications on low-cost embedded devices. In this work, we aim to lower the dynamic power of a stream-based CNN hardware accelerator by reducing the computational redundancies in the CNN layers. In particular, we investigate the redundancies due to the downsampling effect of max pooling layers which are prevalent in state-of-the-art CNNs, and propose an approximation method to reduce the overall computations.
- Categories:
87 Views
- Read more about SOLVING MEMORY ACCESS CONFLICTS IN LTE-4G STANDARD
- Log in to post comments
- Categories:
7 Views