
- Read more about Fast and Parallel Computation of the Discrete Periodic Radon Transform on GPUs, multi-core CPUs and FPGAs
- Log in to post comments
The Discrete Periodic Radon Transform (DPRT) has many important applications in reconstructing images from their projections and has recently been used in fast and scalable architectures for computing 2D convolutions. Unfortunately, the direct computation of the DPRT involves O(N^3) additions and memory accesses that can be very costly in single-core architectures.
- Categories:
 10 Views
10 Views
- Read more about GLOBAL FOR COARSE AND PART FOR FINE: A HIERARCHICAL ACTION RECOGNITION FRAMEWORK
- Log in to post comments
- Categories:
15 Views
- Read more about Fast 2D Convolutions and Cross-Correlations Using Scalable Architectures
- Log in to post comments
The manuscript describes fast and scalable architectures and associated algorithms for computing convolutions and cross-correlations. The basic idea is to map 2D convolutions and cross-correlations to a collection of 1D convolutions and cross-correlations in the transform domain. This is accomplished through the use of the Discrete Periodic Radon Transform (DPRT) for general kernels and the use of SVD-LU decompositions for low-rank kernels.
- Categories:
8 Views
This work presents an automatic method for optical flow inpainting. Given a video, each frame domain is endowed with a Riemannian metric based on the video pixel values. The missing optical flow is recovered by solving the Absolutely Minimizing Lipschitz Extension (AMLE) partial differential equation on the Riemannian manifold. An efficient numerical algorithm is proposed using eikonal operators for nonlinear elliptic partial differential equations on a finite graph.
- Categories:
18 Views
- Read more about GESTALT INTEREST POINTS WITH A NEURAL NETWORK FOR MAKEUP-ROBUST FACE RECOGNITION
- Log in to post comments
In this paper, we propose a novel approach for the domain of makeup-robust face recognition. Most face recognition schemes usually fail to generalize well on these data where there is a large difference between the training and testing sets, e.g., makeup changes. Our method focuses on the problem of determining whether face images before and after makeup refer to the same identity. The work on this fundamental research topic benefits various real-world applications, for example automated passport control, security in general, and surveillance.
Poster_A1.pdf
- Categories:
21 Views
Visual attention allows the human visual system to effectively deal with the huge flow of visual information acquired by the retina. Since the years 2000, the human visual system began to be modelled in computer vision to predict abnormal, rare and surprising data. Attention is a product of the continuous interaction between bottom-up (mainly feature-based) and top-down (mainly learning-based) information. Deep-learning (DNN) is now well established in visual attention modelling with very effective models.
- Categories:
16 Views
- Read more about FLOWFIELDS++: ACCURATE OPTICAL FLOW CORRESPONDENCES MEET ROBUST INTERPOLATION
- Log in to post comments
- Categories:
16 Views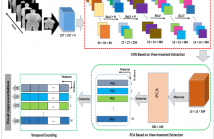
- Read more about DEPTH HUMAN ACTION RECOGNITION BASED ON CONVOLUTION NUERAL NETWORKS AND PRINCIPAL COMPONENT ANALYSIS
- Log in to post comments
In this work, we address human action recognition problem under viewpoint variation. The proposed model is formulated by wisely combining convolution neural network (CNN) model with principle component analysis (PCA). In this context, we pass real depth videos through a CNN model in a frame-wise manner. The view invariant features are extracted by employing convolution layers as mid-outputs and considered as 3D nonnegative tensors.
- Categories:
19 Views
- Read more about DEPTH HUMAN ACTION RECOGNITION BASED ON CONVOLUTION NUERAL NETWORKS AND PRINCIPAL COMPONENT ANALYSIS
- Log in to post comments
In this work, we address human action recognition problem under viewpoint variation. The proposed model is formulated by wisely combining convolution neural network (CNN) model with principle component analysis (PCA). In this context, we pass real depth videos through a CNN model in a frame-wise manner. The view invariant features are extracted by employing convolution layers as mid-outputs and considered as 3D nonnegative tensors.
- Categories:
35 Views