
- Read more about QI-TTS: QUESTIONING INTONATION CONTROL FOR EMOTIONAL SPEECH SYNTHESIS
- Log in to post comments
- Categories:
 29 Views
29 Views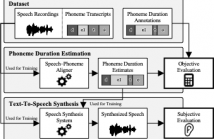
- Read more about Evaluating Speech–Phoneme Alignment and Its Impact on Neural Text-To-Speech Synthesis
- Log in to post comments
In recent years, the quality of text-to-speech (TTS) synthesis vastly improved due to deep-learning techniques, with parallel architectures, in particular, providing excellent synthesis quality at fast inference. Training these models usually requires speech recordings, corresponding phoneme-level transcripts, and the temporal alignment of each phoneme to the utterances. Since manually creating such fine-grained alignments requires expert knowledge and is time-consuming, it is common practice to estimate them using automatic speech–phoneme alignment methods.
- Categories:
34 Views
- Read more about saito22icassp_slide
- Log in to post comments
We propose novel deep speaker representation learning that considers perceptual similarity among speakers for multi-speaker generative modeling. Following its success in accurate discriminative modeling of speaker individuality, knowledge of deep speaker representation learning (i.e., speaker representation learning using deep neural networks) has been introduced to multi-speaker generative modeling.
- Categories:
60 Views
- Read more about One TTS Alignment To Rule Them All
- Log in to post comments
Speech-to-text alignment is a critical component of neural text-to-speech (TTS) models. Autoregressive TTS models typically use an attention mechanism to learn these alignments on-line. However, these alignments tend to be brittle and often fail to generalize to long utterances and out-of-domain text, leading to missing or repeating words. Most non-autoregressive end-to-end TTS models rely on durations extracted from external sources. In this paper we leverage the alignment mechanism proposed in RAD-TTS and demonstrate its applicability to wide variety of neural TTS models.
- Categories:
68 Views
- Read more about iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
- Log in to post comments
We propose iSTFTNet, which replaces some output-side layers of the mel-spectrogram vocoder with the inverse short-time Fourier transform (iSTFT) after sufficiently reducing the frequency dimension using upsampling layers, reducing the computational cost from black-box modeling and avoiding redundant estimations of high-dimensional spectrograms. During our experiments, we applied our ideas to three HiFi-GAN variants and made the models faster and more lightweight with a reasonable speech quality.
- Categories:
41 Views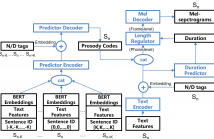
- Read more about DISCOURSE-LEVEL PROSODY MODELING WITH A VARIATIONAL AUTOENCODER FOR NON-AUTOREGRESSIVE EXPRESSIVE SPEECH SYNTHESIS
- Log in to post comments
To address the issue of one-to-many mapping from phoneme sequences to acoustic features in expressive speech synthesis, this paper proposes a method of discourse-level prosody modeling with a variational autoencoder (VAE) based on the non-autoregressive architecture of FastSpeech. In this method, phone-level prosody codes are extracted from prosody features by combining VAE with FastSpeech, and are predicted using discourse-level text features together with BERT embeddings. The continuous wavelet transform (CWT) in FastSpeech2 for F0 representation is not necessary anymore.
ppt.pptx
- Categories:
33 Views
- Read more about SPEECHSPLIT2.0: UNSUPERVISED SPEECH DISENTANGLEMENT FOR VOICE CONVERSION WITHOUT TUNING AUTOENCODER BOTTLENECKS
- Log in to post comments
poster.pdf
- Categories:
43 Views
- Read more about Improving Cross-lingual Speech Synthesis with Triplet Training Scheme
- Log in to post comments
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training.
- Categories:
19 Views