
- Read more about INTRA-FRAME CONTEXT-BASED OCTREE CODING FOR POINT-CLOUD GEOMETRY
- Log in to post comments
- Categories:
 4 Views
4 Views
- Read more about AESTHETICS ASSESSMENT OF IMAGES CONTAINING FACES
- Log in to post comments
poster.pdf
- Categories:
7 Views
- Read more about CONSTANT QUALITY CONTROL BASED ON TEMPORAL DISTORTION BACKPROPAGATION IN HEVC
- Log in to post comments
CQC_v3.pdf
- Categories:
2 Views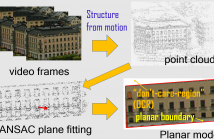
- Read more about RD-OPTIMIZED 3D PLANAR MODEL RECONSTRUCTION & ENCODING FOR VIDEO COMPRESSION
- Log in to post comments
Conventional video coding approaches follow a hybrid motion prediction / residual transform coding paradigm, which limits the discovery of redundancy to individual pairs of video frames.
On the other hand, computer vision techniques like structure-from-motion (SfM) have long exploited redundancy across a large group of frames to estimate a rigid 3D object structure.
In this paper, leveraging on previous SfM techniques, we construct a rate-distortion (RD) optimized 3D planar model from a target spatial region in a frame group as a unified signal predictor for these frames.
- Categories:
18 Views
- Read more about A STUDY ON THE 4D SPARSITY OF JPEG PLENO LIGHT FIELDS USING THE DISCRETE COSINE TRANSFORM
- Log in to post comments
In this work we study the 4D sparsity of light fields using as main tool the 4D-Discrete Cosine Transform. We analyze the two JPEG Pleno light field datasets, namely the lenslet-based and the High- Density Camera Array (HDCA) datasets. The results suggest that the lenslets datasets exhibit a high 4D redundancy, with a larger inter-view sparsity than the intra-view one. For the HDCA datasets, there is also 4D redundancy worthy to be exploited, yet in a smaller degree. Unlike the lenslets case, the intra-view redundancy is much larger than the inter-view one.
icip-2018-4d-dct.pdf
- Categories:
24 Views
This work presents a thresholding method for processing the predicted samples in the state-of-the-art High Efficiency Video Coding (HEVC) standard. The method applies an integer-based approximation of the discrete cosine transform to an extended prediction block and sets transform coefficients beneath a certain threshold to zero. Transforming back into the sample domain yields the improved prediction signal. The method is incorporated into a software implementation that is conforming to the HEVC standard and applies to both intra and inter predictions.
- Categories:
14 Views
- Read more about Low Complexity Joint RDO of Prediction Units Couples for HEVC Intra Coding
- Log in to post comments
HEVC is the latest block-based video compression standard, outperforming H.264/AVC by 50% bitrate savings for the same perceptual quality. An HEVC encoder provides Rate-Distortion optimization coding tools for block-wise compression. Because of complexity limitations, Rate-Distortion Optimization (RDO) is usually performed independently for each block, assuming coding efficiency losses to be negligible.
- Categories:
21 Views
- Read more about Autoencoder-based image compression: can the learning be quantization independent?
- Log in to post comments
- Categories:
19 Views
- Read more about LEARNING-BASED COMPLEXITY REDUCTION AND SCALING FOR HEVC ENCODERS
- Log in to post comments
- Categories:
12 Views
- Read more about A JOINT SOURCE CHANNEL ARITHMETIC MAP DECODER USING PROBABILISTIC RELATIONS AMONG INTRA MODES IN PREDICTIVE VIDEO COMPRESSION
- Log in to post comments
In this paper, residual redundancy in compressed videos is exploited to alleviate transmission errors using joint source channel arithmetic decoding. A new method is proposed to estimate a priori probability in MAP metric of H.264 intra modes decoder. The decoder generates a decoding tree using a breadth first search algorithm. An introduced statistical model is then implemented stage by stage over the decoding tree.
- Categories:
22 Views