- Virtual reality and 3D imaging
- Quality Assessment
- Haptic technology and interaction
- Hardware and software for multimedia systems
- Bio-inspired multimedia systems and signal processing
- Multimedia communications and networking
- Multimedia computing systems and applications
- Multimodal signal processing
- Multimedia security and content protection
- Multimedia human-machine interface and interaction
- Multimedia databases and digital libraries
- Read more about GLMB 3D SPEAKER TRACKING WITH VIDEO-ASSISTED MULTI-CHANNEL AUDIO OPTIMIZATION FUNCTIONS
- Log in to post comments
Speaker tracking plays a significant role in numerous real-world human robot interaction (HRI) applications. In recent years, there has been a growing interest in utilizing multi-sensory information, such as complementary audio and visual signals, to address the challenges of speaker tracking. Despite the promising results, existing approaches still encounter difficulties in accurately determining the speaker’s true location, particularly in adverse conditions such as
- Categories:
 23 Views
23 Views- Read more about A BI-PYRAMID MULTIMODAL FUSION METHOD FOR THE DIAGNOSIS OF BIPOLAR DISORDERS
- Log in to post comments
Previous research on the diagnosis of Bipolar disorder has mainly focused on resting-state functional magnetic resonance imaging. However, their accuracy can not meet the requirements of clinical diagnosis. Efficient multimodal fusion strategies have great potential for applications in multimodal data and can further improve the performance of medical diagnosis models. In this work, we utilize both sMRI and fMRI data and propose a novel multimodal diagnosis model for bipolar disorder.
- Categories:
17 Views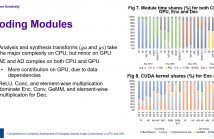
- Read more about Comprehensive Complexity Assessment of Emerging Learned Image Compression on CPU And GPU
- Log in to post comments
Learned Compression (LC) is the emerging technology for compressing image and video content, using deep neural networks. Despite being new, LC methods have already gained a compression efficiency comparable to state-of-the-art image compression, such as HEVC or even VVC. However, the existing solutions often require a huge computational complexity, which discourages their adoption in international standards or products.
- Categories:
42 Views
- Read more about SPATIO-TEMPORAL GRAPH CONVOLUTIONAL NETWORKS FOR CONTINUOUS SIGN LANGUAGE RECOGNITION
- Log in to post comments
ICASSP_poster_4541.pdf
- Categories:
53 Views
- Read more about Melon Playlist Dataset: A Public Dataset For Audio-based Playlist Generation And Music Tagging
- Log in to post comments
One of the main limitations in the field of audio signal processing is the lack of large public datasets with audio representations and high-quality annotations due to restrictions of copyrighted commercial music. We present Melon Playlist Dataset, a public dataset of mel-spectrograms for 649,091 tracks and 148,826 associated playlists annotated by 30,652 different tags. All the data is gathered from Melon, a popular Korean streaming service. The dataset is suitable for music information retrieval tasks, in particular, auto-tagging and automatic playlist continuation.
icassp2021.pdf
- Categories:
42 Views
- Read more about A Viewport-Adaptive Rate Control Approach for Omnidirectional Video Coding
- 1 comment
- Log in to post comments
For omnidirectional videos (ODVs), the existing o-line coding approaches are designed based on the spatial or perceptual distortion in a whole ODV frame, ignoring the fact that subjects can only access viewports. To improve the subjective quality inside the viewports, this paper proposes an o-line viewport-adaptive rate control (RC) approach for ODVs in high eciency video coding (HEVC) framework. Specically, we predict the viewport candidates with importance weights and develop a viewport saliency detection model.
DCC21.pptx
- Categories:
68 Views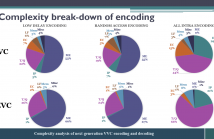
- Read more about Complexity Analysis Of Next-Generation VVC Encoding and Decoding
- Log in to post comments
While the next generation video compression standard, Versatile Video Coding (VVC), provides a superior compression efficiency, its computational complexity dramatically increases. This paper thoroughly analyzes this complexity for both encoder and decoder of VVC Test Model 6, by quantifying the complexity break-down for each coding tool and measuring the complexity and memory requirements for VVC encoding/decoding.
- Categories:
139 Views

- Read more about Automatic identification of speakers from head gestures in a narration
- Log in to post comments
In this work, we focus on quantifying speaker identity information encoded in the head gestures of speakers, while they narrate a story. We hypothesize that the head gestures over a long duration have speaker-specific patterns. To establish this, we consider a classification problem to identify speakers from head gestures. We represent every head orientation as a triplet of Euler angles and a sequence of head orientations as head gestures.
- Categories:
52 Views
- Read more about Presentation: Trapezoidal Segment Sequencing: A Novel Approach for Fusion of Human-produced Continuous Annotations
- Log in to post comments
Generating accurate ground truth representations of human subjective experiences and judgements is essential for advancing our understanding of human-centered constructs such as emotions. Often, this requires the collection and fusion of annotations from several people where each one is subject to valuation disagreements, distraction artifacts, and other error sources.
- Categories:
56 Views